



LOL英雄联盟经典模式预约领皮肤
柴郡猫
·

GPT-5.5生物漏洞赏金
OpenAI
·


AI 范式雷达:《OrchRM——多智能体编排的自监督奖励建模新范式》
Micropaper
·



PORTool:重视重要性的政策优化与奖励树在多工具集成推理中的应用
Apple Machine Learning Research
·
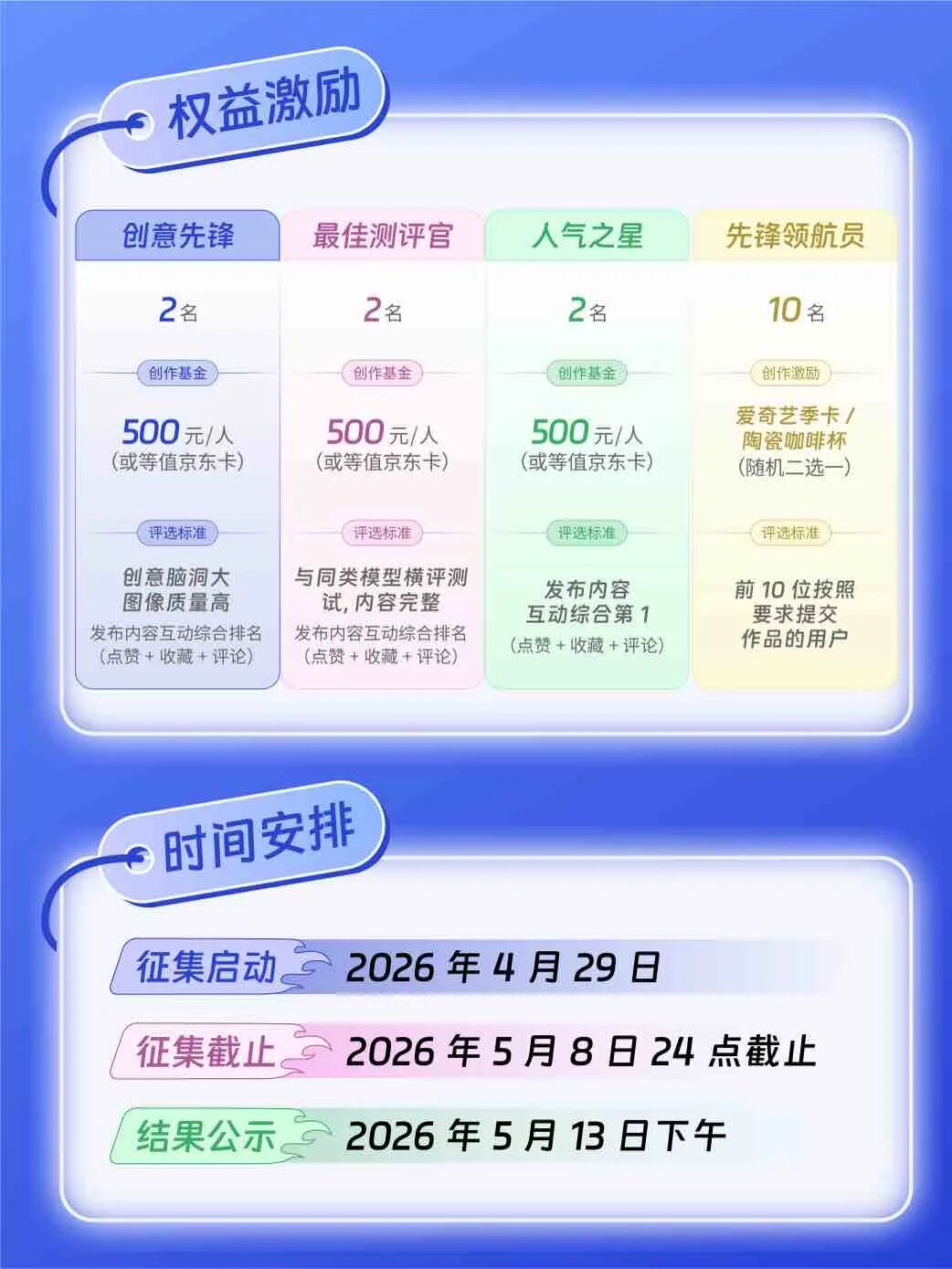
Goldilocks强化学习:调节任务难度以应对稀疏奖励的推理
Apple Machine Learning Research
·
