

令人印象深刻的AI演示已死。实际上,什么才会进入生产阶段
The New Stack
·

令牌效率:将更多信号引入上下文窗口
Redis Blog
·
知识图谱增强生成 (RAG):面向 AI 代理的结构化检索
Redis Blog
·
您的代理已达到上下文限制。以下是应对方案
Redis Blog
·



-xe390kzia0.png)
在Azure上使用MongoDB Atlas构建AI就绪的数据基础
MongoDB
·

如何利用边缘计算构建智能工厂
The New Stack
·

什么是数据架构?组成部分、原则与实例
BMC Software | Blogs
·



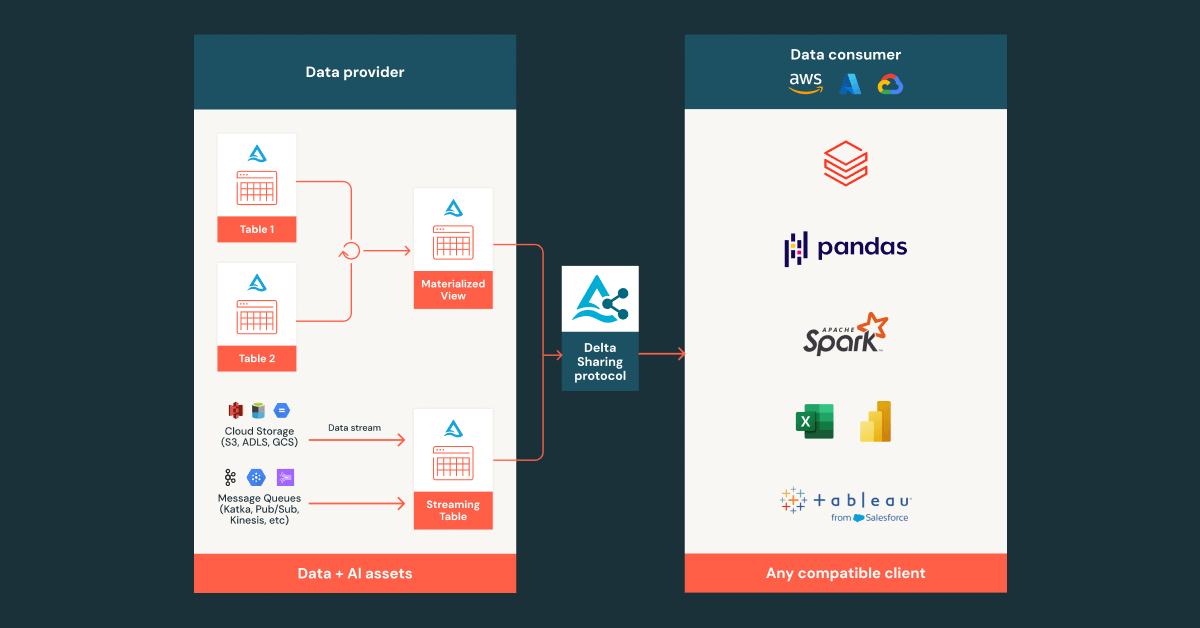
宣布流式表和物化视图共享的公开预览
Databricks
·

当单一技术栈不足时:使用本地FaaS协调多语言数据处理管道
DEV Community
·

开始使用无服务器架构:您需要了解的顶级工具
DEV Community
·

使用.NET Core、SignalR和Azure构建实时数据处理系统
DEV Community
·

无服务器数据流处理与Aurora DSQL
DEV Community
·
