AWS推出了多智能体协调器框架,旨在高效管理多个AI智能体,处理复杂对话场景。该系统能够智能路由查询、维护交互上下文,并与多种部署环境无缝集成,支持Python和TypeScript,适合企业管理多样化的AI应用。
本研究提出了ClarQ-LLM评估框架,用于对话模型澄清能力评估。该框架包含31种不同任务类型的对话场景,提高了模型在对话中询问澄清问题的测试。现有的寻求者代理在测试中表现不佳,为未来研究提供了挑战。
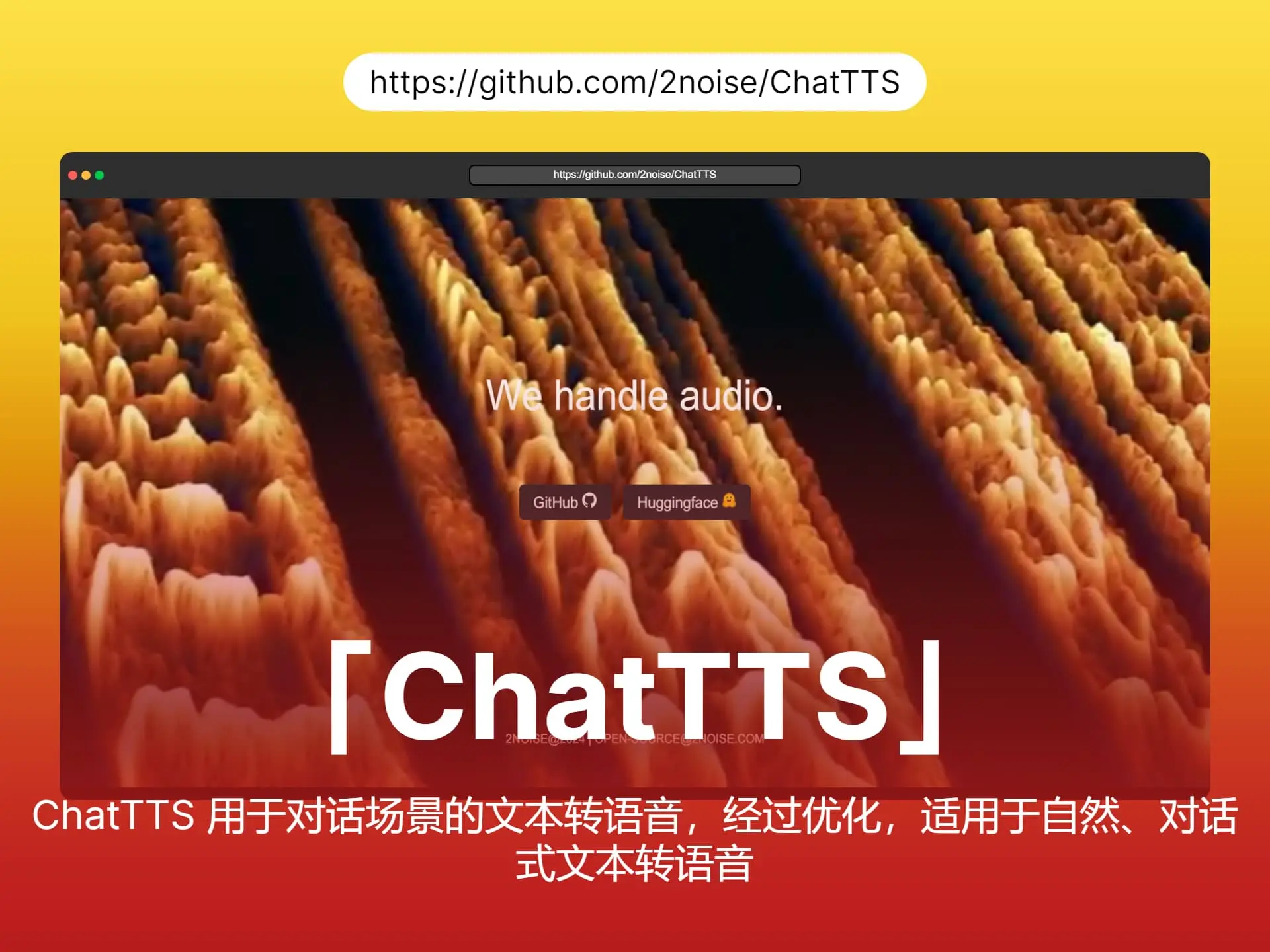
ChatTTS是一种专为对话场景设计的文本转语音模型,可以免费在Colab上托管。本文提供了部署该项目的说明,并介绍了其特点,如语音选择和生成长音频。
ChatTTS是一个适用于对话场景和语音合成的文本到语音转换模型,支持中英文,通过大量数据训练,生成高质量和自然度的语音。使用ChatTTS的基本步骤包括下载代码库、安装依赖项、导入库、初始化ChatTTS、准备文本、生成语音和播放音频。开发人员可以通过API和SDK将ChatTTS集成到应用程序中。
自动化测试在对话场景中的必要性体现在节省时间和提高效率上。手动测试需要耗费大量时间,而自动化测试可以快速检测出失败的 case,然后手动测试这些 case。此外,自动化测试的 test case 可以用于现场演示,保证演示的成功率。对于简单规则场景,可以使用 test_stories.yml 文件进行测试。测试结果会显示通过的 case 和失败的 case,可以查看具体哪个 story 失败了。
完成下面两步后,将自动完成登录并继续当前操作。