
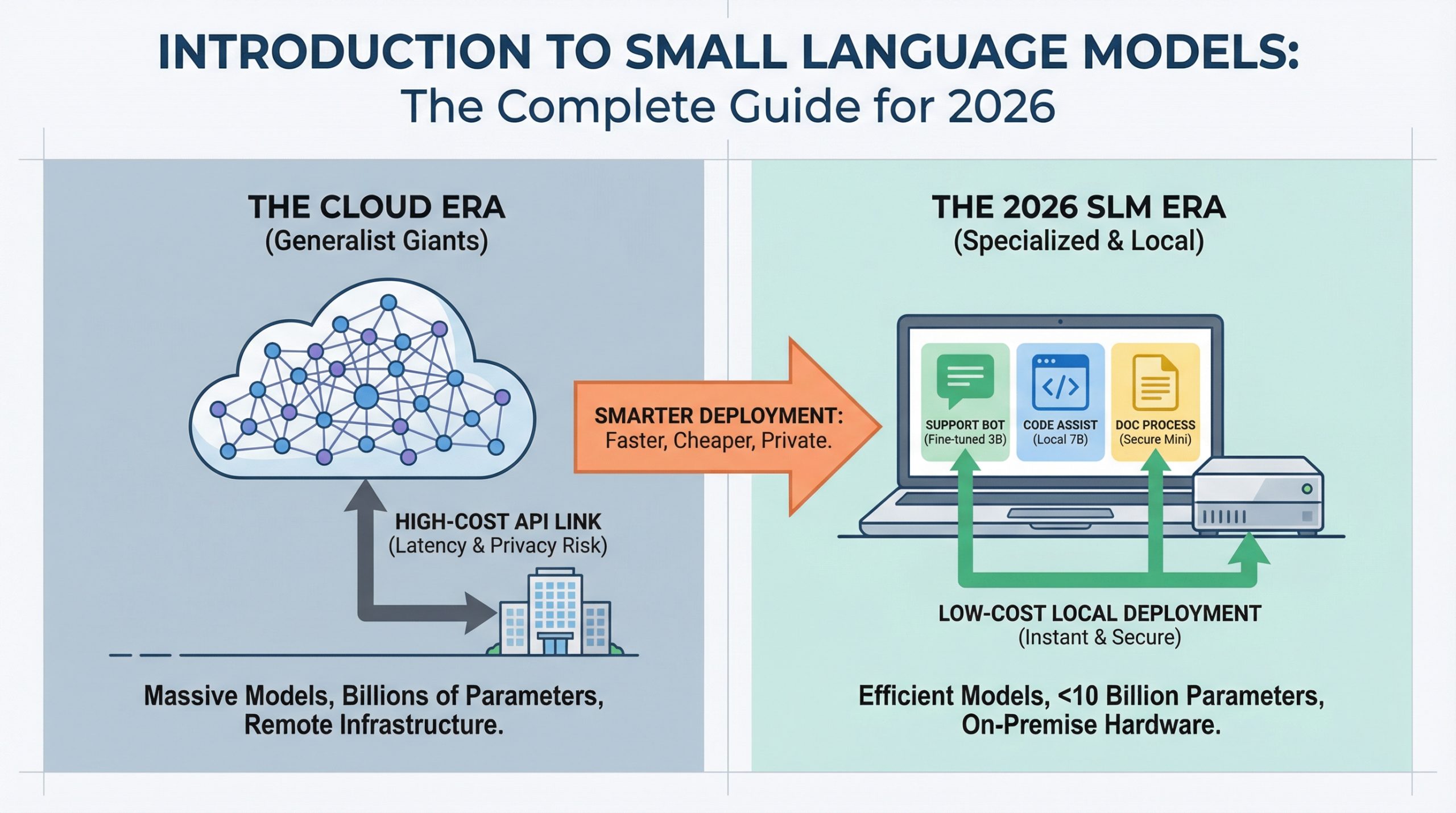
小语言模型简介:2026年完整指南
MachineLearningMastery.com
·


NVIDIA RTX通过LTX-2和ComfyUI升级加速PC上的4K AI视频生成
NVIDIA Blog
·



边缘计算中小语言模型(SLMs)的高效资源管理
InfoQ
·


AMD 发布 AMD-135M:开源小语言模型
实时互动网
·

