Go语言表面简单,实则复杂。初学者可能会被其简约设计吸引,但在深入开发中,诸如并发、运维和错误处理等挑战逐渐显现。精通Go需要理解其哲学、核心概念及标准库的深层机制。
机器之心数据服务现已上线,提供高效、稳定的数据获取,简化数据爬取流程。
文章描绘了主人公在灵山的思考与回忆,反映了对自由与理想的追求。通过对乡村生活的怀念,揭示了欲望的虚无与追寻的荒谬,最终意识到真正的自由在于接受欲望的无限性与幻象。
本文分析了大型语言模型中的幻觉现象,并提出了一种交互自我反思的方法以减少幻觉。研究表明,训练数据的记忆和频率偏好是主要原因。通过实验,构建了一个准确率达88%的分类器来检测幻觉,并探讨了缓解幻觉的策略,以提高模型的可靠性,旨在改善人工智能在健康信息传播中的准确性。
最近大规模语言模型在摘要系统的能力方面取得了重大进展;然而,仍然存在关于虚构信息的担忧。本研究评估了对话摘要中大语言模型的准确性,使用人工注释,并着重于识别和分类分段级别的不一致性。通过比较行为差异,我们提出了一种错误的细分分类方法,并引入了两种基于提示的方法以更好地检测这些细微错误。
本研究探讨了大型语言模型(LLMs)在决策中的应用,构建了LIFECHOICE数据集,发现LLMs在人物驱动决策中具有潜力但需改进。提出了CHARMAP方法以提升准确率,并分析了LLMs的幻觉现象,开发了分类方法和减少幻觉的策略,旨在提高模型在实际任务中的可靠性和准确性。
自主系统使用基础模型进行决策的应用方向有前途,但基础模型存在不合理决策问题。本研究讨论了基础模型在决策任务中的应用案例,给出了幻觉的定义和示例,并探讨了幻觉检测和减轻的方法,同时探索了进一步研究方向。
深度学习目标检测对视力受损者避开障碍物有帮助。评估七种不同的YOLO目标检测模型,发现YOLOv8在道路和人行道上的表现最佳,精确度为80%,召回率为68.2%。YOLO-NAS在其他应用中表现更好,但对于障碍物检测任务来说不理想。
研究发现,GPT系列的调整模型在理解意图和信念方面表现优于其他模型和儿童。指令调整模型的增加可能与语言和心智理论的互相关联有关。建议对语言模型中的心智理论保持细致观点。
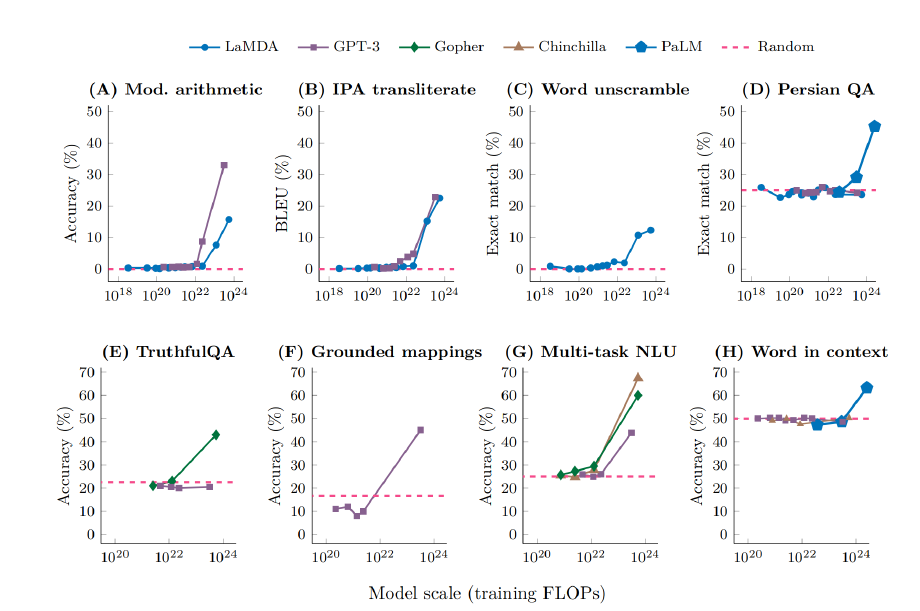
研究人员发现,大规模语言模型的涌现能力是由于衡量指标的选择,而非模型行为的根本性变化。非线性或不连续的衡量标准会导致明显的涌现能力,而线性或连续的度量标准会导致模型性能的平滑、连续、可预测的变化。涌现能力的消失与指标选择相关,不是大规模模型的基本属性。该论文于去年4月底发布,并获得最佳论文奖。
最近的语言模型在生成对外观听起来真实但实际上是虚假的文本方面存在神秘的倾向,这对于基于语言的人工智能系统的可用性构成了障碍,并可能对依赖其输出的人造成伤害。本研究表明,预训练语言模型出现虚构某些类型的事实的统计原因是固有的,与变压器 LM 架构或数据质量无关。对于那些无法从训练数据中确定真实性的 “任意”...
本文研究了大型语言模型幻觉的检测、解释和缓解方法,提出了幻觉现象的分类和评估基准,分析了现有的缓解方法,并探讨了未来研究的潜在方向。
题面https://www.luogu.com.cn/problem/P1363题解先说正解。怎么样才能判断可以无限延伸呢?那就是如果存在一条路径$$P \rightsquigarrow P'$...
文章讨论了如何判断虚幻棋盘上是否存在无限延伸的路径。通过证明路径的映射关系,得出若存在无限路径,则必有对应的路径形式。反证法表明,若路径长度有限,则无法达到无限延伸,形成矛盾。文中还指出了一些常见的错误结论,并提供了相关代码示例。
最近很火的“躺平”、“饮茶”梗,还有更之前的“佛系”,其实这些梗意思都差不多,而且也差不多无聊,这些梗除了是城市小布尔乔亚的嘴上说说之外什么都不是,只是一句随便说说罢了。未明子会睿评说这种躺平其实是有代价的,而且把代价转移到了发不出声音的真正底层被压迫者身上,来维持自己能够享受躺平的廉价商品。我的分析比他后撤一步——也许现在的躺平确实是不需要代价的,因为有代价的是真的躺,而现在只是嚷嚷。 一...
完成下面两步后,将自动完成登录并继续当前操作。