文章探讨了操作系统在应对AI工作负载和异构计算时的挑战与未来发展方向,重点包括调度、内存管理、I/O优化及内核旁路技术的演变。强调操作系统需关注控制路径,支持CXL内存革命和安全性提升,以实现硬件抽象和资源公平分配。
编译器工程正在转型,传统的单一中间表示(IR)设计无法满足AI和异构计算的需求。MLIR通过“方言”和“渐进降阶”整合编译链,提升优化能力。本系列旨在填补学习MLIR的空白,涵盖基础概念到实际应用的系统性内容,帮助开发者理解其设计哲学与实现路径。
2026年,AI产业将进入高强度算力周期,Token成为核心资源。算力需支持复杂AI应用,国产算力面临新机遇。洪源指出,需解决集群服务能力、计算效率和生态问题,以适应Token经济和AI应用的增长。未来,算力将贯穿模型研发到应用部署,成为关键基础设施。
蔚蓝科技推出的BabyAlpha A3消费级四足机器人,具备6600万像素视觉和223.2万点/秒的空间感知能力,标志着机器人向理解环境的转变。A3采用六颗芯片的异构计算集群,提升算力效率,预计售价万元级,旨在进入普通家庭。其安全设计和本地数据处理增强了用户信任,推动消费级具身智能的发展。
GPU、TPU和NPU是AI计算的三大核心处理器,分别适用于大规模并行计算、云端AI优化和低功耗设备。未来硬件分工将更加细化,异构计算将成为常态,以提高算力效率。
清华大学KVCache.AI团队与趋境科技推出KTransformers项目,支持在24G显存下运行DeepSeek-R1,显著提升推理速度。该项目通过异构计算和CPU的AMX指令集加速,预填充速度达到286 tokens/s,生成速度为14 tokens/s,降低了大模型的运行门槛,推动了本地部署的可能性。
研究人员提出了MagicPIG,通过在CPU上应用局部敏感哈希(LSH)技术,显著提升了大模型解码吞吐量1.76至4.99倍,减轻了GPU内存压力,并提高了推理质量和准确率。这项研究探索了异构计算的潜力,有望降低模型部署成本。
高通公司在2024全球AI芯片峰会上宣布其领先的SoC解决方案提供了异构计算系统和高性能低功耗的NPU,满足生成式AI的不同需求和算力要求。他们展示了终端侧生成式AI在旗舰终端和用例中的应用,并介绍了NPU硬件架构和AI体验,包括支持大语言模型的NPU和多模态大模型的完整运行。高通强调终端侧生成式AI的重要性,并预告了下一代骁龙移动平台的发布。
SHIFT方法通过利用上下文信息和计算约束,选择多种物体检测模型,提高能源利用效率和降低延迟。相比GPU单模型方法,能源使用提升7.5倍,延迟提升2.8倍。
科学计算需求增加,OpenCL在异构计算领域流行,但调度困难。MultiCL通过扩展OpenCL标准,实现自适应调度,缓解调度难题。MultiCL提供不同调度方法,解决OpenCL的性能可移植性问题。MultiCL包含设备分析器、内核分析器和任务调度器,实现动态调度。但MultiCL引入预执行开销,降低执行效率,需要进一步优化。
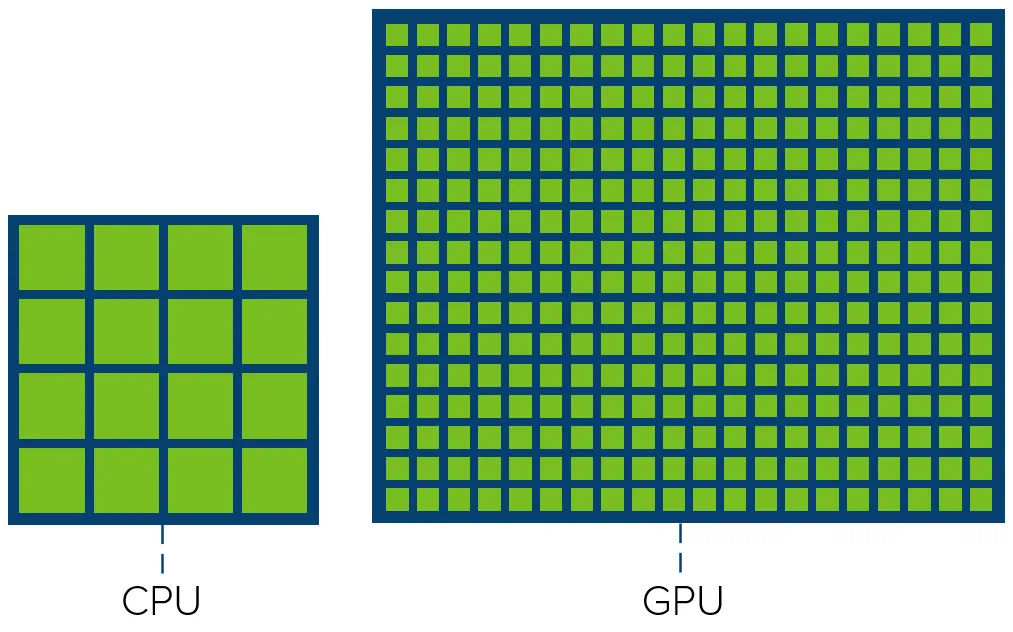
GPU和CPU在计算任务上有不同的适用性。GPU适合处理数据并行的计算密集型任务,而CPU适合处理控制密集型任务。NVIDIA的GPU计算平台有多个产品系列,包括Tegra、GeForce、Quadro、Tesla等。CUDA是一种通用的并行计算平台和编程模型,提供了运行时API和驱动API来管理GPU设备和组织线程。数据局部性在并行编程中很重要,包括时间局部性和空间局部性。
CPU和GPU的异构计算演进体现在设计理念和应用领域的差异。CPU适合通用计算,追求高效能和低能耗;而GPU专注于图形处理和机器学习,具备更高的并行处理能力。随着技术发展,GPU引入了张量核心和光线追踪核心,以满足AI和图形渲染的需求。这反映了计算需求的多样化和专用化趋势。
完成下面两步后,将自动完成登录并继续当前操作。