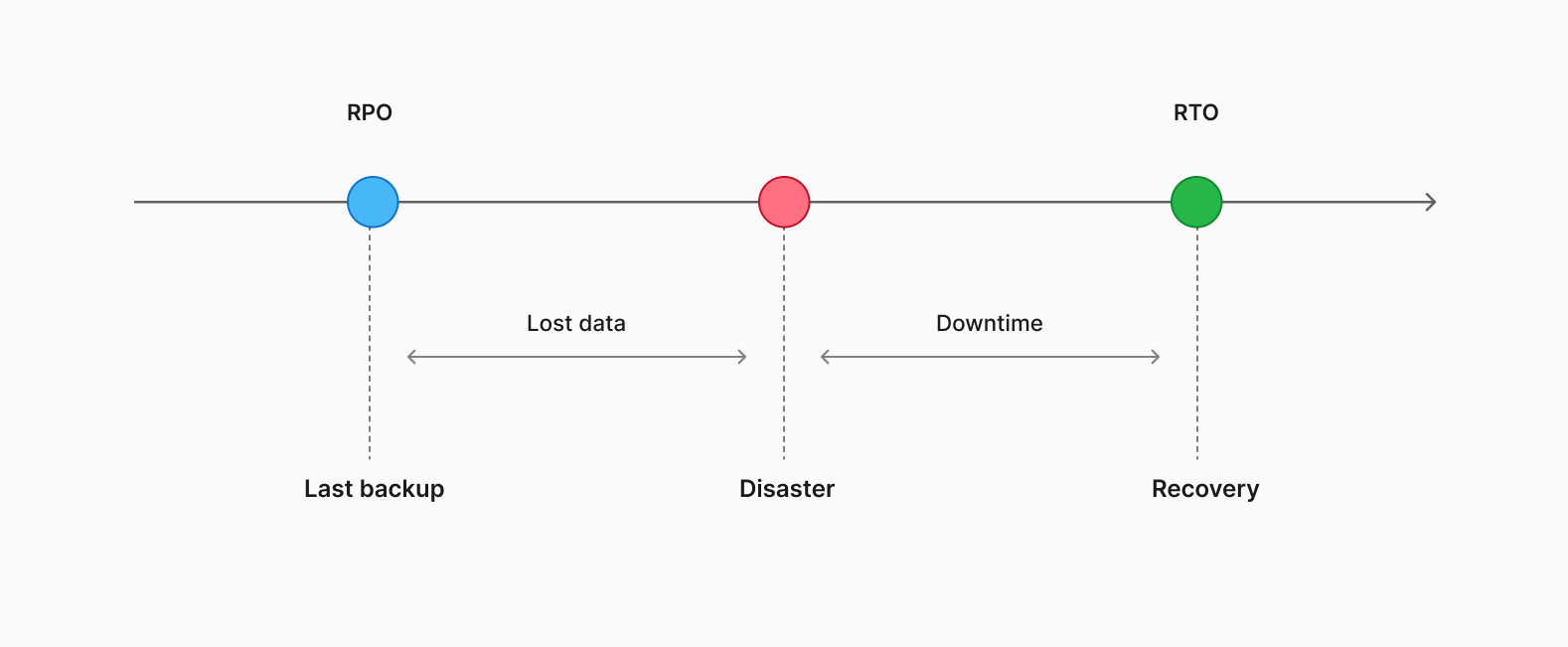
PostgreSQL的高可用性应采用分层设计,首先明确故障范围、恢复点目标(RPO)和恢复时间目标(RTO)。从单主节点开始,逐步引入离线备份、WAL归档和热备份,最终实现多站点灾难恢复。每一层增加特定能力,以确保系统的稳定性和可恢复性,避免高压操作。
在数字时代,系统停机可能导致企业损失数百万。灾难恢复(DR)策略确保在硬件故障、网络攻击或自然灾害时,业务能够持续运作。关键指标包括恢复时间目标(RTO)和恢复点目标(RPO)。了解故障转移机制对于实现高可用性和减少停机至关重要。有效的DR策略能降低风险,确保快速恢复。
客户期望无缝体验,尤其在Kubernetes应用普及的背景下,确保业务连续性至关重要。IT团队需定义恢复点目标(RPO)和恢复时间目标(RTO),以减少数据丢失和停机时间。复杂的Kubernetes环境要求灵活的灾难恢复解决方案,支持同步和异步恢复,以满足关键应用需求。
构建数据库灾难恢复计划时,需要区分高可用性(HA)和灾难恢复(DR)。HA旨在减少停机时间,而DR关注在重大故障后的业务恢复。设定恢复点目标(RPO)和恢复时间目标(RTO)至关重要,备份策略应与之匹配。使用MySQL复制和备份策略可以提高恢复效率,自动化恢复过程并定期测试计划,以确保在灾难发生时能够迅速有效地恢复系统。
Amazon Resilience Hub是亚马逊云科技的托管服务,可为应用程序定义恢复时间目标和恢复点目标,并提供建议和韧性得分。该服务可发现由Amazon CloudFormation部署的应用程序,也可从资源组和标签中发现应用程序,或从AppRegistry中选择。通过实践,Amazon Resilience Hub可以帮助快速定位和解决问题,使应用程序能够持续满足业务连续性的要求。
最近,Point-in-Time恢复(PITR)功能已向更多项目开放,用户可通过新仪表板轻松启用。该功能允许数据库在特定时间点恢复,以避免数据丢失。启用PITR需满足“小型”计算附加组件,并考虑恢复点目标(RPO)。默认备份保留期为7天,可延长至28天。
完成下面两步后,将自动完成登录并继续当前操作。