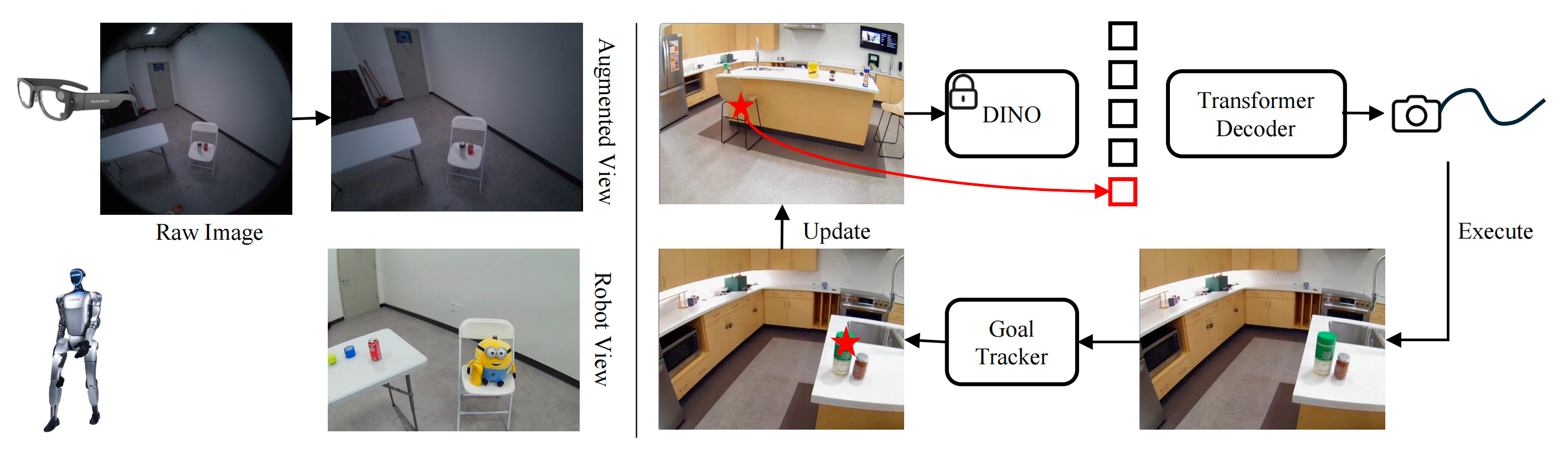
HEAD是一种人形机器人手眼自主递送系统,结合导航、运动与触达任务。通过模块化方法,利用人类数据训练机器人在复杂环境中高效完成目标操作,成功率达到71%。未来可扩展至更复杂的抓取任务。
本文介绍了一种新型视觉语言模型(VLM),结合物理概念和语言指令,提升机器人在抓取和放置任务中的表现。通过大规模视频生成预训练,模型在多任务操作中展现出显著的泛化能力。RoboPoint模型在空间可行性预测上优于现有技术,成功率提高30.5%。RoboUniView方法通过统一视图表示,提升了机器人在不同摄像机参数下的适应性和性能。
完成下面两步后,将自动完成登录并继续当前操作。