OpenTelemetry与Prometheus之间存在兼容性问题,主要由于OpenTelemetry缺乏服务发现和主动拉取功能。Prometheus专注于指标监控,而OpenTelemetry生成多种信号并传递给第三方系统。两者的集成需要在性能和语义约定方面改进,未来可能通过合成上报指标来解决健康检查问题。
近年来,游戏服务的可观测性成为提升产品质量和运维效率的关键。通过建立可观测性体系,技术团队能够实时监控游戏服务、检测异常并分析问题,从而优化用户体验。本文分享了在游戏服务中应用OpenTelemetry的实践经验,包括链路追踪、指标监控和日志管理,探讨了面临的挑战及解决方案。
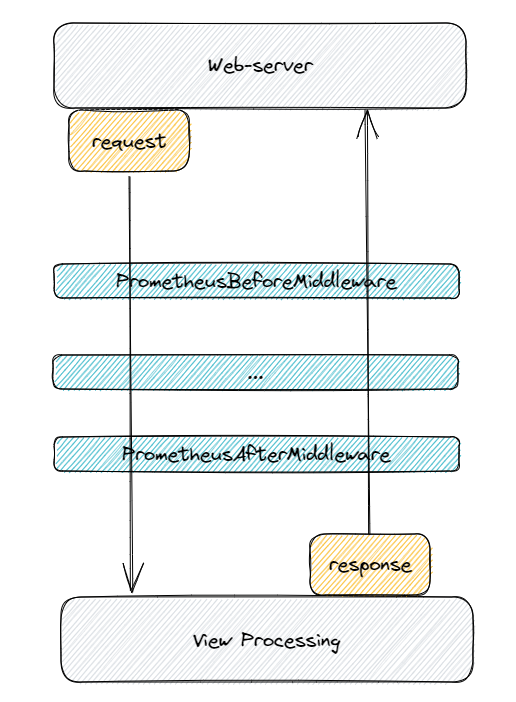
本文介绍了如何在Django服务中使用django-prometheus监控Prometheus指标,以实时了解服务状态并进行优化。通过配置中间件和路由,可以收集请求、数据库和缓存等指标,并分析源码实现,提供示例代码,说明如何处理多进程和单进程的指标收集。
本文介绍了从0到100万用户的扩展过程,包括单服务器配置、数据库选择、负载均衡器、数据库复制、缓存、内容分发网络、无状态网络层、消息队列、记录日志和收集指标等。同时提供了系统设计面试的框架和设计限流器、一致性哈希系统、键值存储系统、唯一ID生成器、URL缩短器、网络爬虫、通知系统、news feed系统、聊天系统、搜索自动补全系统、视频分享系统、云盘、支付系统、指标监控和告警系统的设计方法。
本文介绍了K8s集群CoreDNS监控告警的最佳实践,使用CCE集群插件kube-prometheus-stack进行指标监控,通过AOM2.0服务展示和通知告警。文章列举了coreDNS的关键指标,包括请求速率、请求数据包大小、响应速率、响应时延、缓存。最后介绍了配置和触发coreDNS的告警规则。
华为云应用运维管理平台通过中国信通院检验,达到可观测性平台技术先进级水平。该平台实时监控应用及云资源,采集并关联各项指标、日志及事件等数据,提供灵活告警和数据可视化功能。助力企业提高软件系统质量和效率,优化业务流程和方向,提高业务决策质量。
本文介绍了Go语言中的expvar包及其与expvarmon工具的结合使用。expvar包用于暴露Go应用的内部指标数据,用户只需导入该包并启动HTTP服务器即可访问指标。expvarmon工具可实时监控这些指标,并支持将数据持久化到CSV文件中,便于后续分析和可视化展示。
完成下面两步后,将自动完成登录并继续当前操作。