DuckDB是一种嵌入式列式数据库,结合Go语言可实现每秒写入1800万条数据,适合大数据分析。与传统关系型数据库相比,DuckDB通过向量化执行和原生支持Parquet格式显著提升查询性能,且无需复杂的集群部署,适合轻量级分析,尤其在处理Nginx日志时表现优异。但不适合高并发的在线事务处理。
华为云DWS推出AI数仓能力,解决传统数据仓库的存储冗余和运维复杂问题。新版本集成MCP协议,支持实时推理和多模态分析,提升开发效率,助力企业数字化转型。
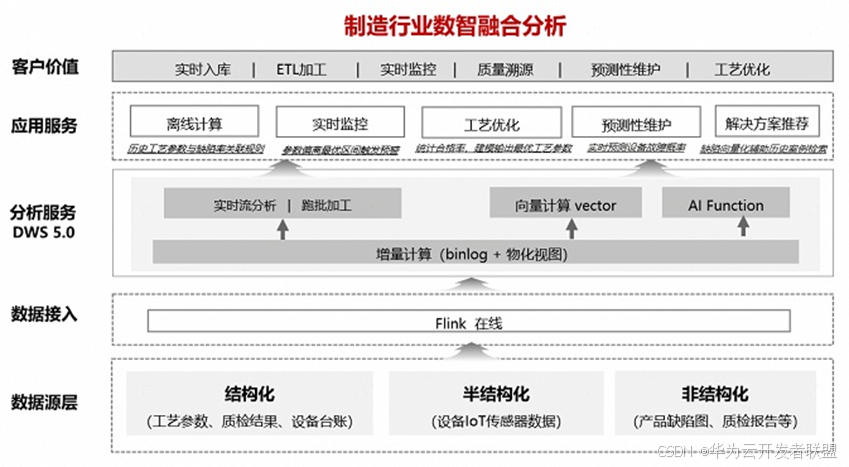
DWS实时数仓解决方案支持分层和增量加工,实现数据的实时入库、出库和查询,确保数据新鲜度。解决方案与Flink深度融合,简化链路和运维,提高数据处理效率和查询速度。未来将继续深化与Flink的融合,优化存储与计算引擎,提升数据处理性能,拓展应用场景。
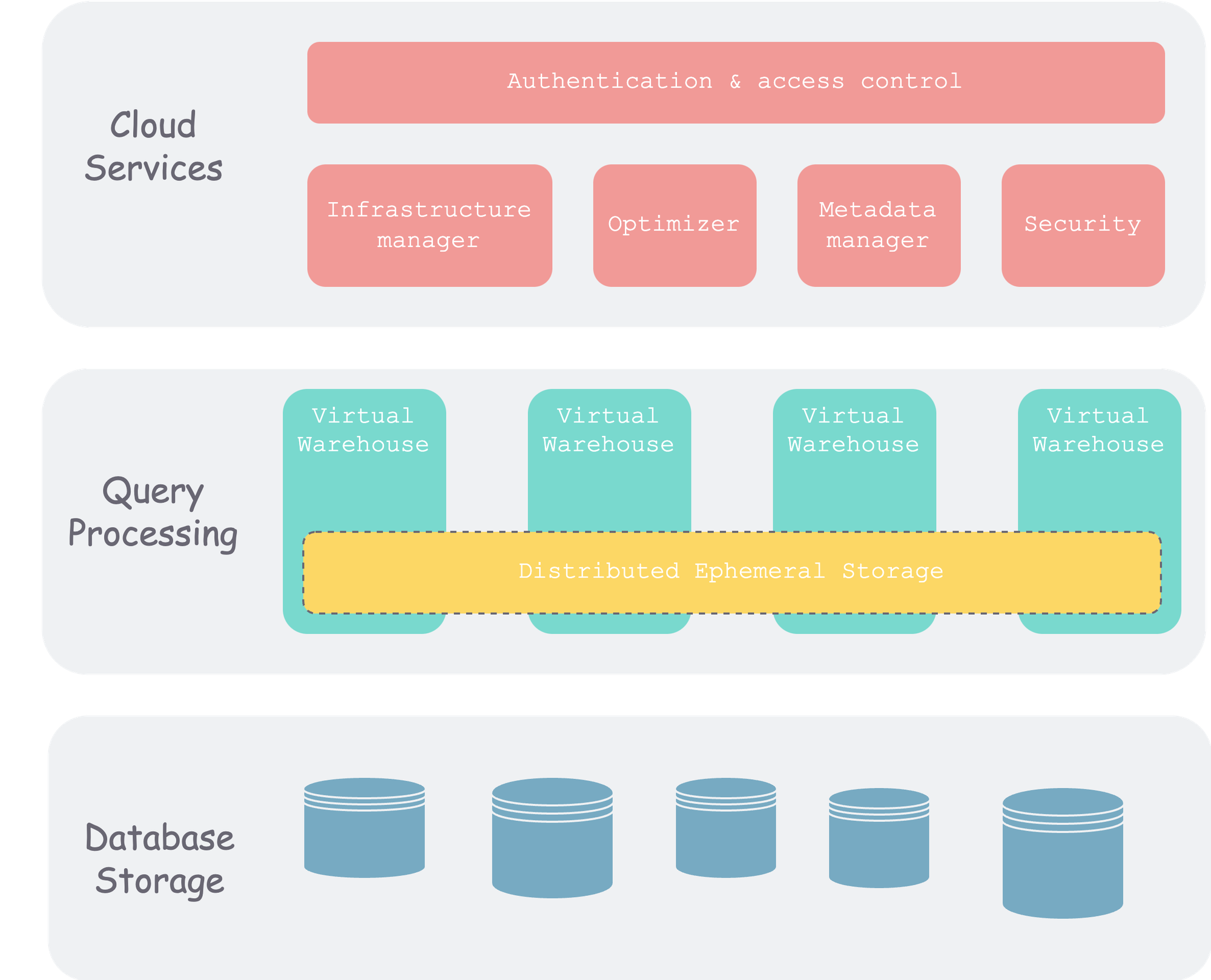
Snowflake是一种云原生数据仓库,具有存算分离、多租户和高性能等特点。它的架构包括存储层、计算层和元信息层。
华为云数仓产品GaussDB(DWS)是备受瞩目的数仓产品之一,具备丰富的GP迁移成功经验,易使用、高性能、易扩展、高可靠、低成本。华为云GaussDB(DWS)已成为国内数据仓库中的佼佼者,帮助1700+大客户规模商用。未来,GaussDB(DWS)将继续深耕云原生Serverless化、实时分析、湖仓一体、数智融合、HTAP等数仓核心技术。
本文介绍了GaussDB(DWS)数据脱敏功能的原理和使用方法,包括动态脱敏、脱敏策略创建和绑定等。还介绍了可算不可见功能和防护恶意套取的方法。数据脱敏实时处理查询语句,具有优势和应用场景。
本文介绍了GaussDB(DWS) 3A安全能力,包括认证、授权和审计。
本文介绍了GaussDB(DWS)中的向量化执行引擎,该引擎采用一次一批元组的执行模式,能够减少遍历执行节点的开销,提高CPU的有效利用率。向量化引擎与列存储结合,能够在底层扫描节点装填向量化的列数据。文章还介绍了行执行器和列执行器的区别,以及向量化引擎的性能优势。最后,文章提到了GaussDB向量化引擎的演进过程,包括Sonic向量化引擎和Turbo向量化引擎的推出,以及对各种算子的进一步优化。
本文介绍了JSON和JSONB的概念和区别,以及DWS中JSON和JSONB的使用方法和功能。JSON是一种轻量级的数据交换格式,而JSONB是对JSON数据进行解析和存储后的格式。JSON和JSONB的存储方式和性能有所不同,JSON在插入时性能较好,而JSONB在查询时性能较好。文章还介绍了JSON和JSONB的输入格式和常用函数及操作符。总结了DWS中JSON和JSONB的功能和优缺点,并提出了后续的演进路线。
华为云数仓GaussDB(DWS)利用Flink实现实时数仓构建,提供快速分析查询能力。增量计算解决高性能和数据入库问题。GaussDB(DWS)与Flink结合构建下一代Stream Warehouse,实现实时入出仓、实时增量加工和实时查询。GaussDB(DWS)结合Flink的能力包括Catalog、Source、Sink和流维。生态工具streamer简化数据入库操作。
本文介绍了GaussDB(DWS)性能调优中的优化器和系统级GUC参数,包括语句级调优和数据库全局级别的参数配置。通过调整GUC参数可以选择更优的查询计划,提升语句执行性能和整体性能。关键词:GaussDB(DWS)、性能调优、优化器、系统级GUC参数、语句级调优
本文介绍了GaussDB DWS的SQL ON ANYWHERE技术,可以在一个客户端中使用SQL语句操作不同的大数据组件,提升使用效率。通过SQL ON ANYWHERE特性,实现与其他大数据组件和数据库互联互通访问,扩大应用场景。具体实现方式包括利用FDW访问HDFS/OBS数据和通过EC+ODBC实现跨数据库访问。
本文介绍了GaussDB(DWS)数据库中序列SEQUENCE的原理和使用方法,包括创建、修改和删除序列,以及相关函数的使用。总结了SEQUENCE的使用场景和常见问题的解决方法。
企业在进行大数据处理时,需要评判数仓模型的好坏。评判指标包括数据准确性、数据质量、数据模型的建模、数据集成、数据分析的支持程度以及成本效益。
今年JD新增招聘名额,招聘基于DataFusion/Ballista的数仓产品开发工作。
本文介绍了GaussDB(DWS)中的HashJoin-nestloop等待视图的含义和影响。当内存不足时,会通过内外表交换或执行nestloop使查询平稳进行,防止内存报错。建议将参数hashjoin_spill_strategy设置为2以规避问题。
本文介绍了华为云的GaussDB(DWS)存储引擎HStore的优化方法,包括解决小CU问题和提升数据聚簇性。这些方法能够显著提升HStore表的性能。
本文介绍了云上环境双集群后台手动部署和使用细粒度容灾的步骤,包括容灾前准备、细粒度容灾操作和解除容灾。细粒度容灾满足核心分析型业务的连续性要求,降低容灾建设成本,轻量化架构易运维、易操作、易演练。
本文介绍了使用with recursive递归查询的方法来实现查询视图的层级依赖关系。通过建立基表和视图,并使用复杂的组合查询,可以得到视图的依赖关系。然而,这种查询方法不直观且不友好。因此,可以使用with recursive语法来实现递归查询,将查询结果保存为视图,从而实现直观的依赖关系表示。最后,总结了查询视图的重要性和希望本文对读者有所帮助。
阿里云推出Hologres V2.1版本,新增弹性计算组实例、实时湖仓Paimon格式支持、向量计算计算巢方案等功能。优化了CountDistinct、Runtime Filter和Join效率,新增了漏斗、留存、路径等函数,支持BSI+RB函数助力高效画像分析,以及单实例Shard多副本和DataWorks集成等能力。
完成下面两步后,将自动完成登录并继续当前操作。