

数据管道最佳实践:架构、现代管道与部署
Databricks
·

刘桥生:发布 pg_ducklake v1.0
Planet PostgreSQL
·
将分散的知识转化为可信的智能:Stack Internal 2026.3
Stack Overflow Blog
·

如何构建开源数据湖以实现批量摄取
freeCodeCamp.org
·
在Databricks上构建实时产品搜索
Databricks
·
提升工业物联网性能边界:硬件如何影响工业物联网工作负载
Timescale Blog
·
【译】 数据摄取构建模块简介(预览版)(二)
dotNET跨平台
·

如何测量您的IIoT PostgreSQL表
Timescale Blog
·

构建Vertex AI搜索应用程序:全面指南
KDnuggets
·
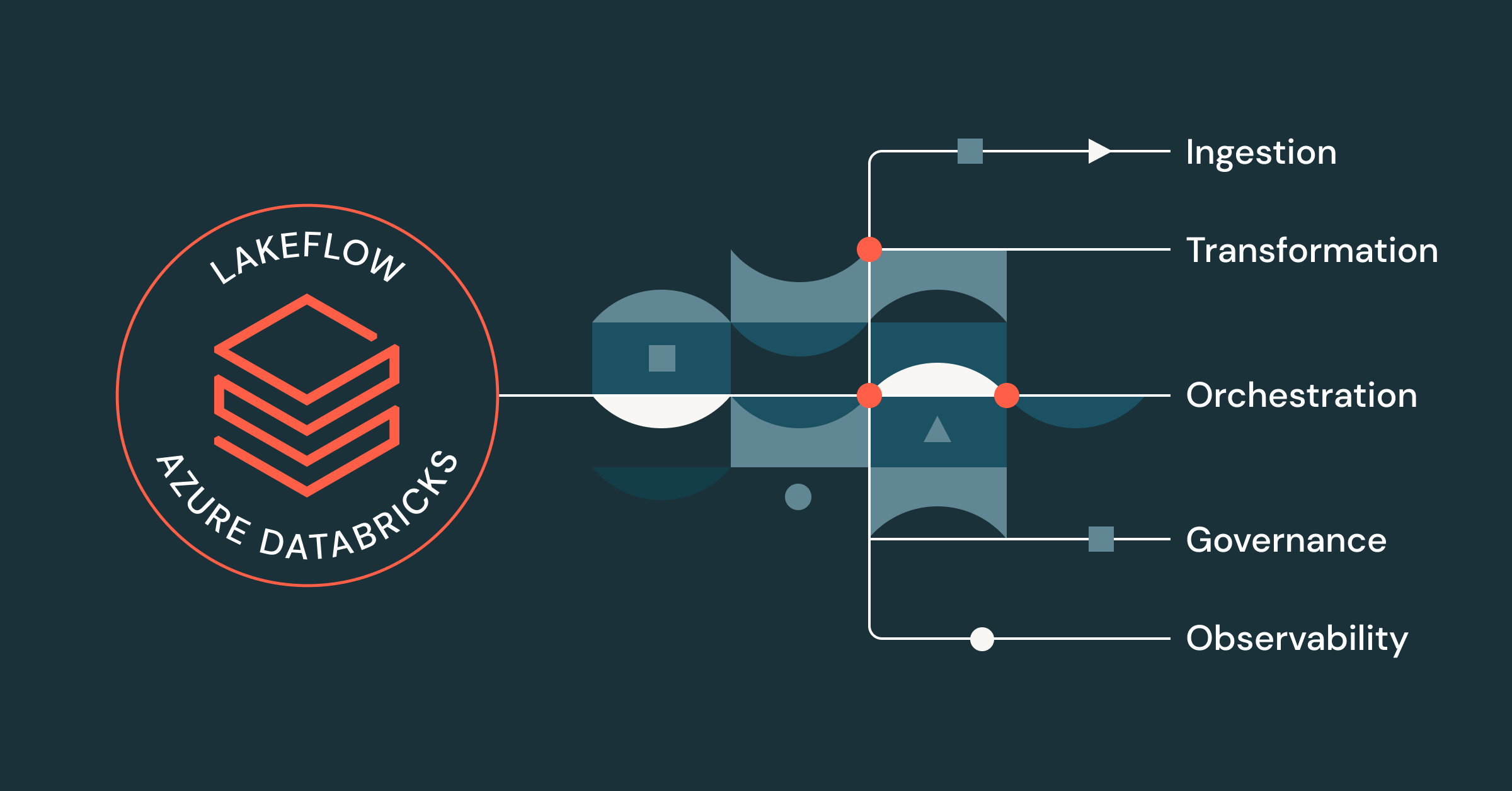
在Azure Databricks上使用Lakeflow现代化您的数据工程平台
Databricks
·

Elastic Cloud Serverless 定价与包装
Elastic Blog - Elasticsearch, Kibana, and ELK Stack
·

宣布 Zerobus Ingest 的公开预览
Databricks
·
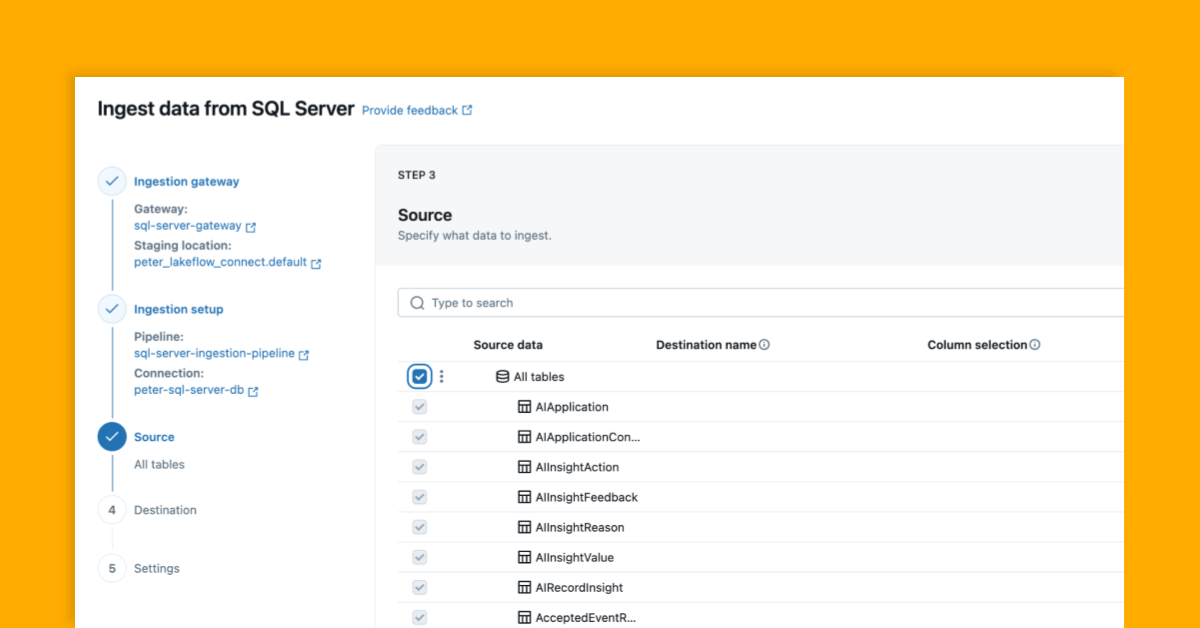
宣布Lakeflow Connect推出SQL Server连接器,现已正式上线
Databricks
·
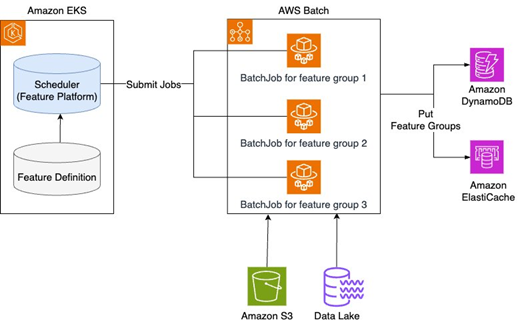
Karrot如何在AWS上构建特性平台,第二部分:特性摄取
AWS Architecture Blog
·

构建Jetflow:Cloudflare灵活高效的数据管道框架
The Cloudflare Blog
·

如何通过自定义日志和数据摄取管道基准测试Elasticsearch性能
Elastic Blog - Elasticsearch, Kibana, and ELK Stack
·

数据工程概念介绍 |2| 理解数据源与数据摄取
DEV Community
·

Cloudflare AutoRAG 简化了检索增强生成
InfoQ
·

使用Python和人工智能进行数据加载
freeCodeCamp.org
·

正式宣布Lakeflow Connect的全面可用性
Databricks
·
