本研究提出了一种新模型,通过结合数据集表格内容和元数据,提高数据集检索的准确率和NDCG得分。测试结果表明,该模型能有效改善无监督和有监督的Web表格检索任务。同时,研究探讨了数据集标签的视觉-语义关系及其在数据交换中的应用,强调了语义数据管理在大数据中的重要性。
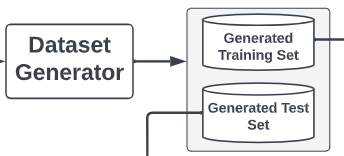
prompt2model是一种通过提示自动生成语言模型的方法,包含Prompt Parser、Dataset Retriever、Dataset Generator和Model Retriever等部分。它利用上下文学习分割用户提示,检索相关数据集,并通过用户反馈优化选择。生成的数据集采用自动提示工程和共识输出过滤,Model Retriever则使用BM25算法根据用户指令检索模型。
完成下面两步后,将自动完成登录并继续当前操作。