

词嵌入与文本向量化的温和介绍
MachineLearningMastery.com
·

谷歌推出基于Gemini的新文本向量化模型
DEV Community
·

小本本系列:大模型中的文本向量text embeddings
Shadow Walker 松烟阁
·

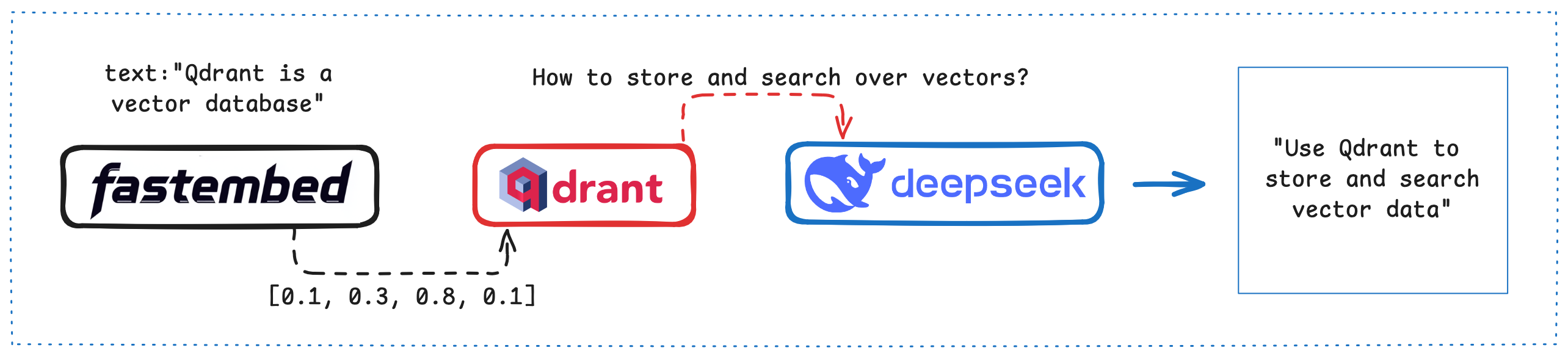
5分钟使用DeepSeek构建RAG
Qdrant - Vector Database
·
