
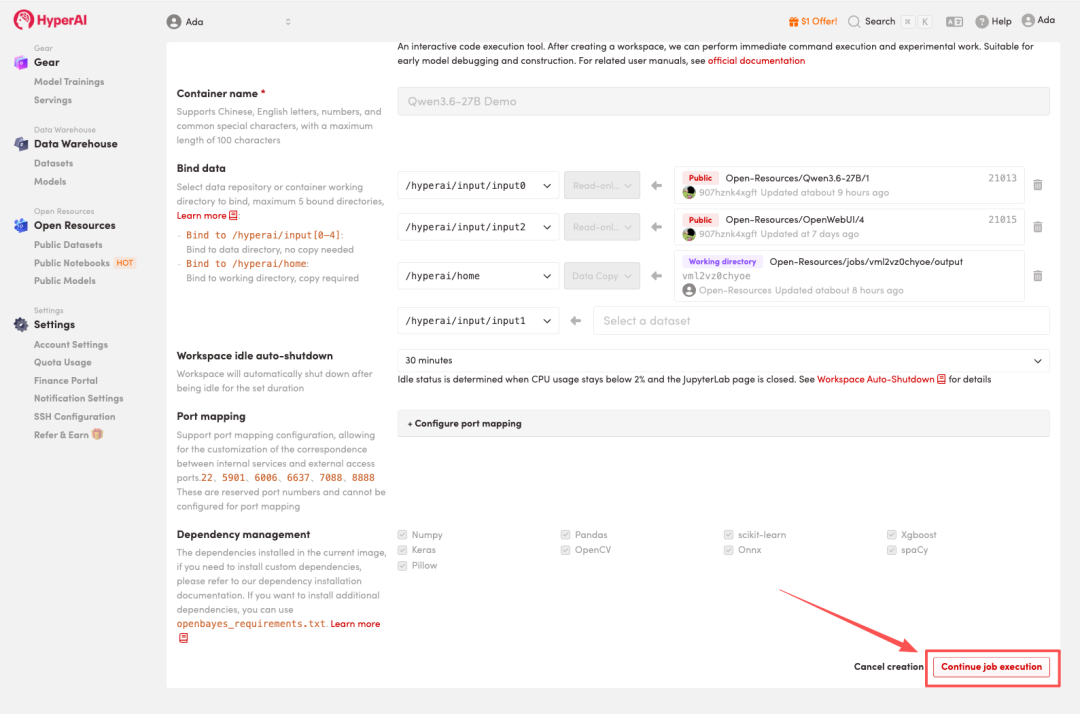
在线教程丨小身材大「码」力,Qwen3.6-27B编程能力达旗舰级
HyperAI超神经
·

谷歌Nano Banana生图大模型使用指南
厦大数据库实验室博客
·

DeepSeek V3能生成图像吗?
DEV Community
·

2025年:人工智能大型概念模型(LCMs)的曙光
DEV Community
·


超越CLIP:Jina-CLIP如何推动多模态搜索
Jina AI
·
