本研究评估了不同文本领域中文档相似性评分的性能,比较了TF-IDF、Word2Vec和BERT嵌入的优缺点。结果显示,TF-IDF依赖于词汇重叠,Word2Vec在跨领域比较中表现优越,而BERT在复杂领域的表现较差,可能是由于缺乏微调。
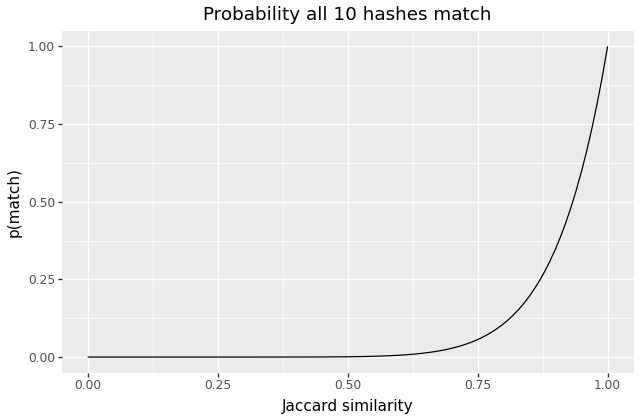
本文探讨了使用Jaccard相似度和MinHash技术进行近似去重的方法。通过设定相似度阈值,可以识别相似文档。Jaccard相似度通过比较集合的交集与并集来衡量相似性,而MinHash则通过生成文档的“签名”来高效估算相似度。这种方法适用于大规模文档集合,有效识别近似重复内容。
完成下面两步后,将自动完成登录并继续当前操作。