
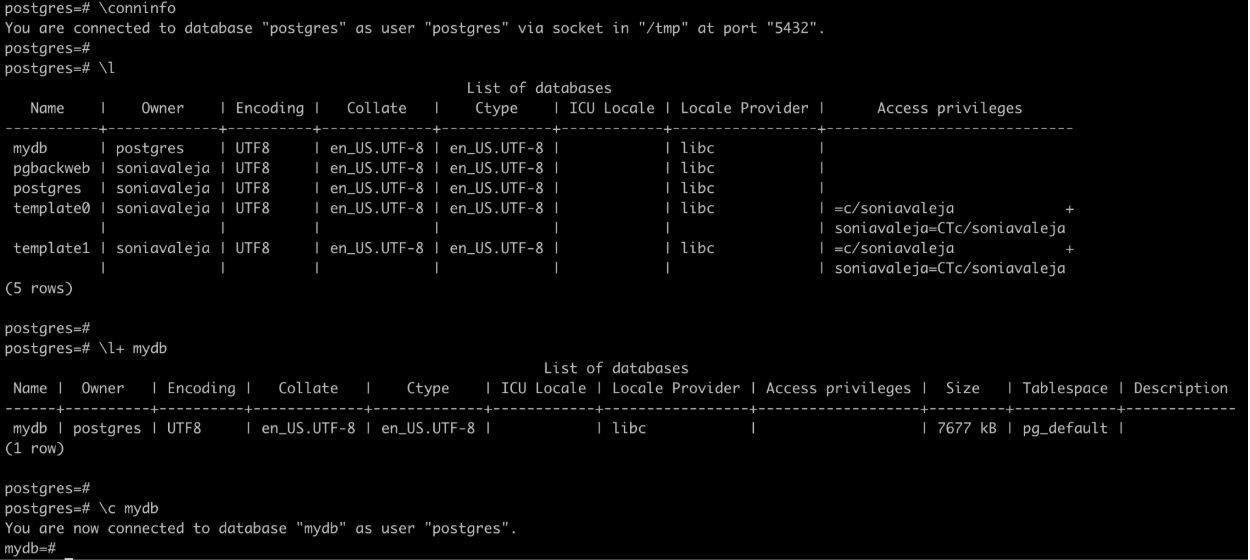
每天节省时间的PostgreSQL元命令
Percona Database Performance Blog
·

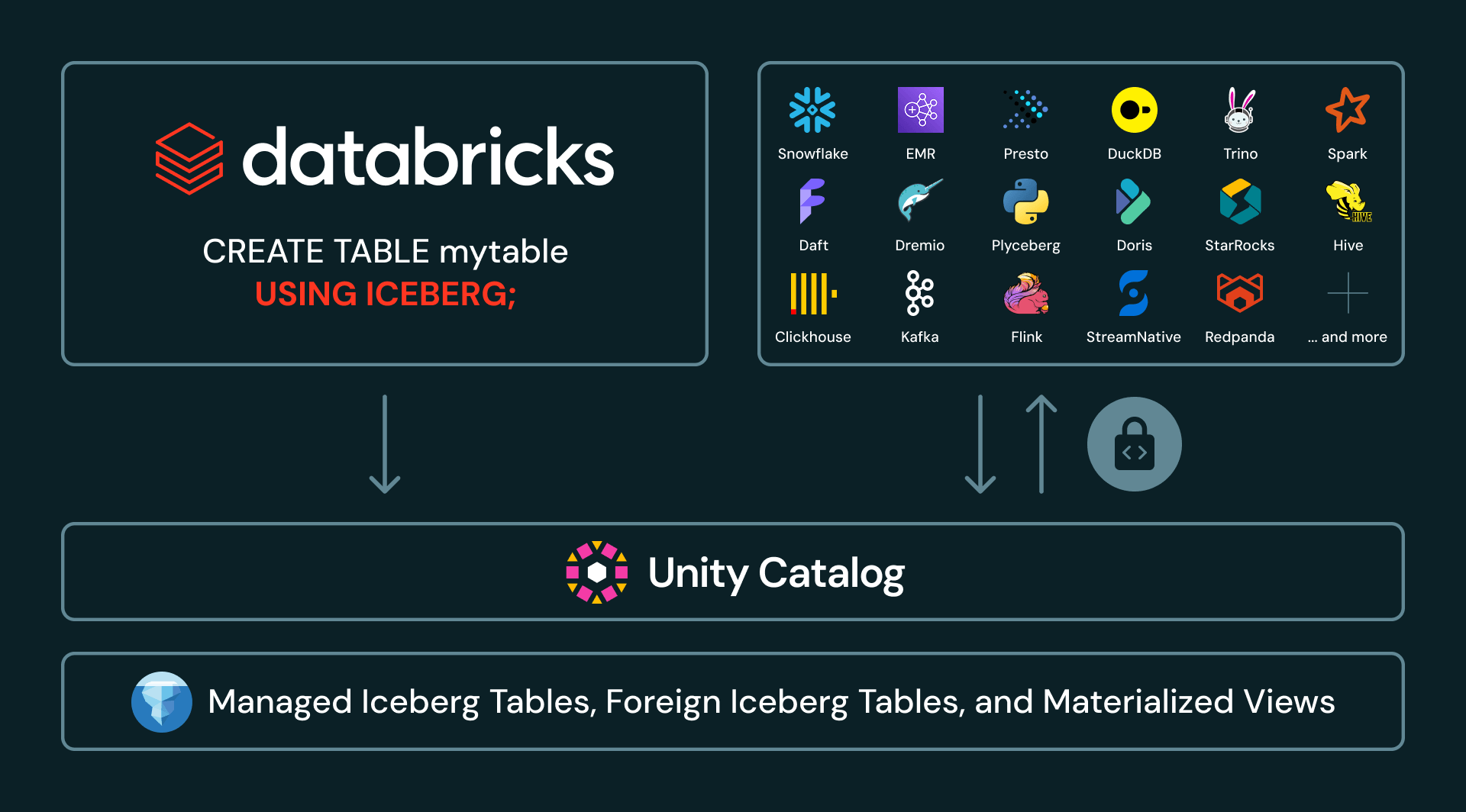
Unity Catalog 与 Apache Iceberg™ 的下一个时代
Databricks
·

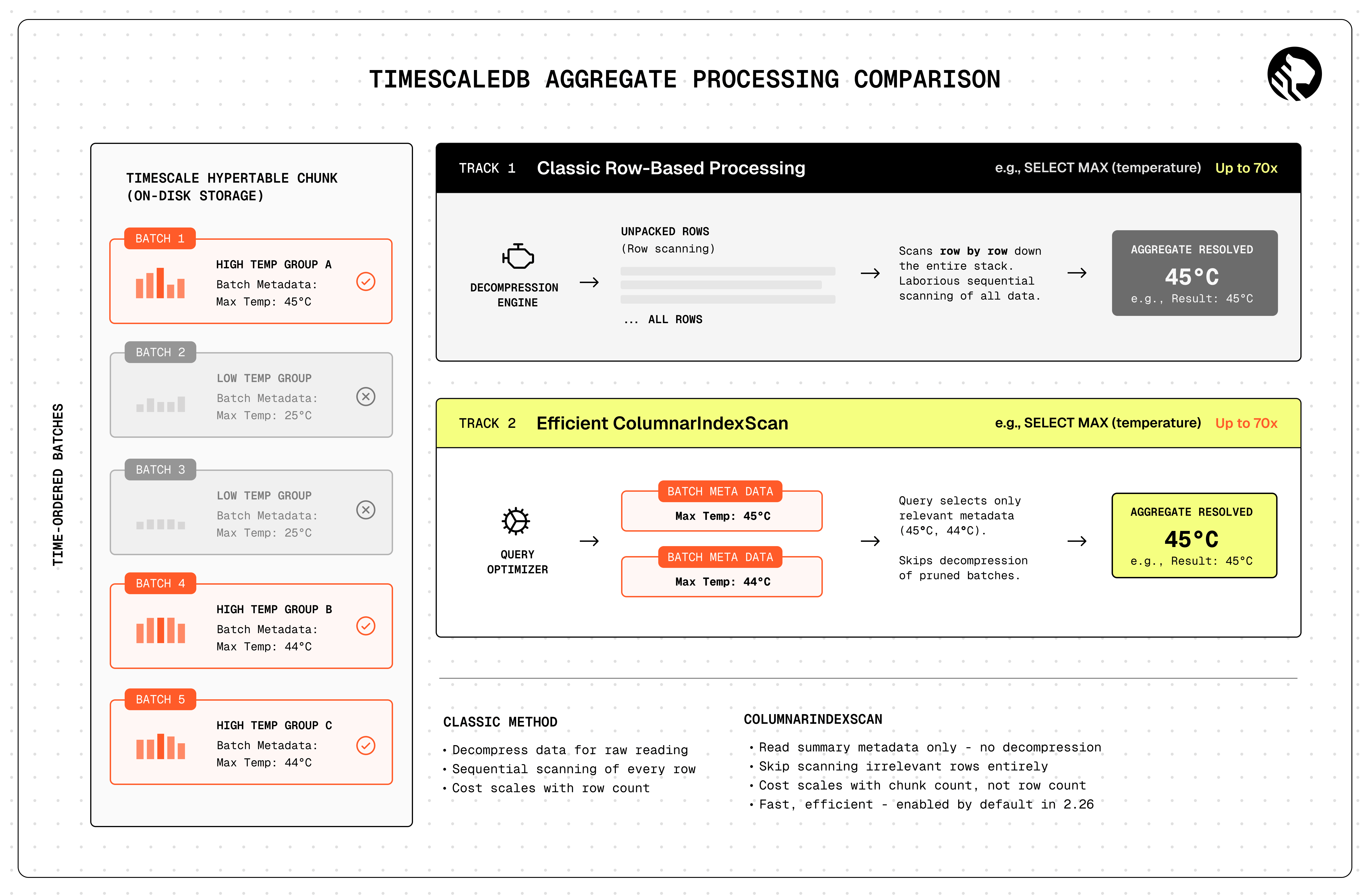
TimescaleDB 2.26:3.5倍更快的 time_bucket() 聚合,70倍更快的摘要查询,以及更快的多列查找
Timescale Blog
·

数据库索引的工作原理 – PostgreSQL实例的实用指南
freeCodeCamp.org
·
