


从pgvector开始:为什么你会比想象中更快地超越它
Qdrant - Vector Database
·

Tiger Cloud的新动态:更快的性能、更简化的工作流程、更加便捷的采用
Timescale Blog
·

与Scanner合作:每条日志都有故事——只要你能足够快地找到它
Sequoia Capital US/Europe
·

Glooko如何利用Tiger Data将每月超过30亿条数据转化为拯救生命的糖尿病医疗服务
Timescale Blog
·

Umair Shahid:PostgreSQL 物化视图:何时缓存查询结果是合理的(何时不合理)
Planet PostgreSQL
·
Arctic Wolf 的液态聚类架构调优至 PB 级规模
Databricks
·

Prisma 7:无Rust架构与性能提升
InfoQ
·

数据库性能优化终极指南
Redis Blog
·

n8n的Redis向量存储节点:您需要了解的内容
Redis Blog
·

革新汽车测量数据存储与分析:梅赛德斯-奔驰在Databricks智能平台上的PB级解决方案
Databricks
·
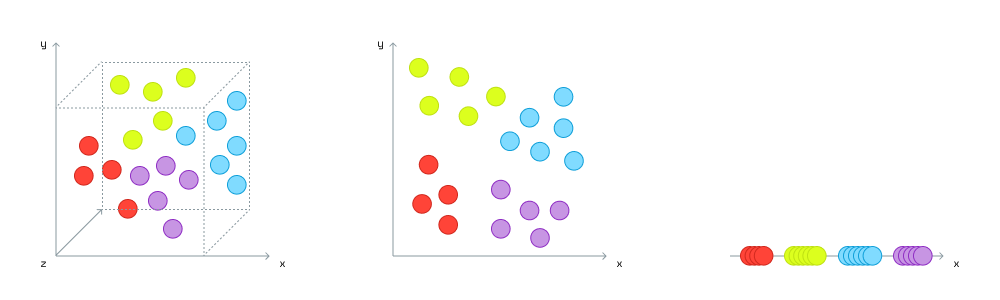
Redis查询引擎现已支持量化和降维技术
Redis Blog
·
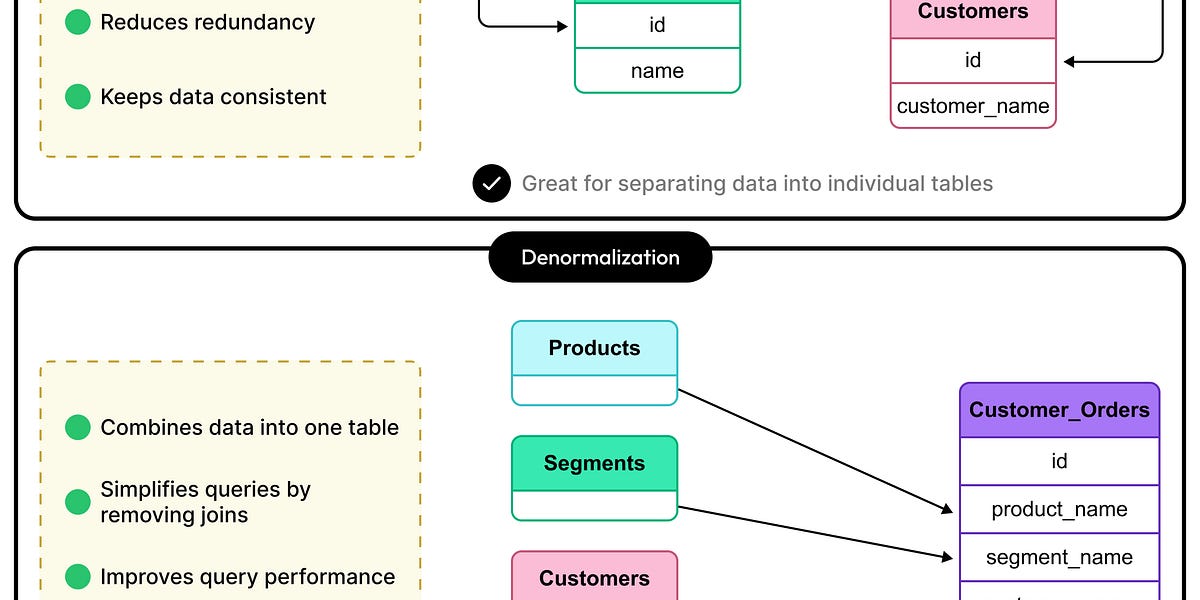
数据库模式设计简化:规范化与非规范化
ByteByteGo Newsletter
·
