在GPT-5.1及后续版本中,模型频繁提及“小妖精”等生物,源于对“书呆子”个性化训练的奖励机制。随着报告增多,问题逐渐显现。分析显示,模型在“书呆子”个性下对生物类比的偏好显著,导致这种现象扩散。最终,开发团队在GPT-5.4中移除了相关个性,减少了这些生物的出现,强调了奖励信号对模型行为的影响。
AI原生基础设施旨在将模型行为、算力稀缺性和不确定性纳入可治理的系统,提供可度量和可进化的边界,确保AI系统在生产环境中的可交付性和治理。关键在于算力治理、工程化执行形态和闭环机制,以应对不确定性,实现可持续发展。
Gemma Scope 2 是一款工具,旨在解析 Gemini 3 模型的行为,帮助研究人员分析模型、审计 AI 代理并制定安全策略。它结合稀疏自编码器和转码器,允许研究人员检查模型内部表示,识别输出与内部状态的差异,并改进了训练技术,特别针对聊天机器人的复杂行为分析。
随着AI系统的不断增强,研究者希望深入理解其行为。OpenAI提出了“忏悔”方法,旨在鼓励模型诚实报告不当行为,从而提升透明度和信任度。实验结果表明,该方法显著提高了模型识别错误的能力,但仍需进一步改进。这为AI安全提供了一种新的工具,有助于监测和诊断模型行为。
本研究提出了一种将概念层集成到大语言模型的方法,以解决可解释性和可干预性不足的问题。该方法通过投影和重构,无需人工选择概念集,能够在多任务中保持性能并有效干预,显示出在调整模型行为方面的良好潜力。
本研究探讨了理解和控制蛋白质语言模型的新方法,采用稀疏自编码器,揭示模型处理蛋白质序列的方式。研究表明,通过操控特征可以引导模型行为,并在生物实验中验证了蛋白质特征检测的改进。
本文探讨了大型语言模型的激活引导技术,提出了一种名为Activation Addition (ActAdd)的方法,通过修改激活预测性地改变模型行为。研究表明,激活工程能够有效引导模型输出特定风格,并提升编程模型的鲁棒性和准确性。此外,Contrastive Activation Addition(CAA)方法显著改善了模型行为控制,超越了传统微调方法。研究还提出了后门激活攻击框架,展示了其在对齐任务中的有效性。
最近的研究发现亚空间干预可以同时操纵模型行为和将特征归因于给定亚空间,但这两个目标是不同的,可能会导致虚假的解释感觉。研究还展示了实践中支持该现象普遍存在的证据。然而,亚空间激活干预在可解释性方面仍然适用。
最近的研究发现亚空间干预可以同时操纵模型行为和将特征归因于给定亚空间,但这两个目标是不同的,可能导致虚假解释感觉。研究还发现亚空间干预可能是通过激活与模型输出因果断开的并行路径来实现的。然而,这并不意味着亚空间激活干预在可解释性方面本质上不适用。研究还探讨了需要的额外证据来论证修补的亚空间是否忠实。
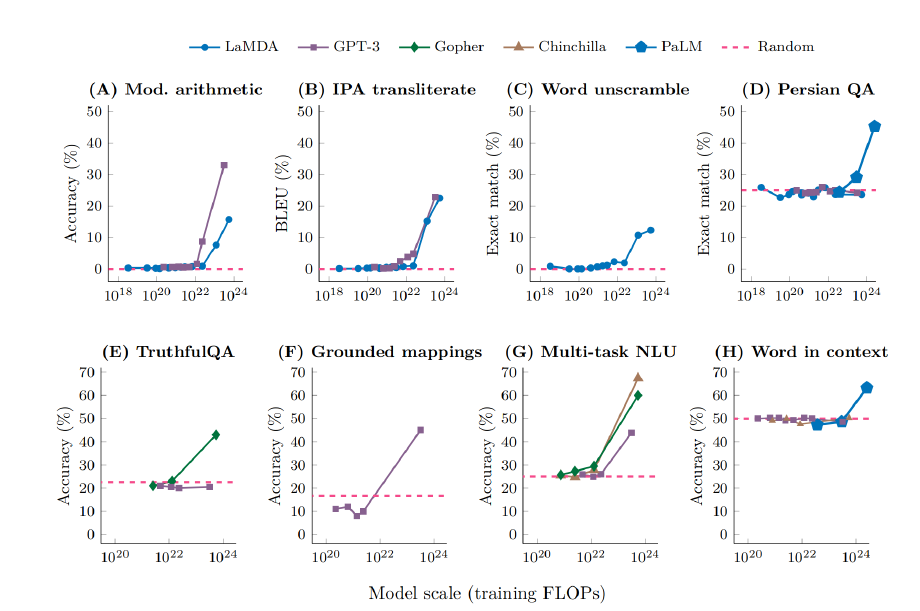
研究人员发现,大规模语言模型的涌现能力是由于衡量指标的选择,而非模型行为的根本性变化。非线性或不连续的衡量标准会导致明显的涌现能力,而线性或连续的度量标准会导致模型性能的平滑、连续、可预测的变化。涌现能力的消失与指标选择相关,不是大规模模型的基本属性。该论文于去年4月底发布,并获得最佳论文奖。
完成下面两步后,将自动完成登录并继续当前操作。