本文介绍了一种可微分全局流本地注意力框架,用于姿势引导的人体图像生成。该模型通过预测流场和提取特征图中的局部补丁,生成高质量的人体图像,实验结果表明其优于传统方法,适用于多种空间变换任务。
论文提出了一种新的卷积轻量化结构MoD,通过动态选择特征图中的关键通道来提高效率。MoD保留静态计算图,提升了训练和推理效率,适用于多种CNN架构。实验结果表明,交替使用MoD块和标准卷积块能有效提升性能。
本文提出了一种新颖的深度感知注意力融合网络,通过特定编码器提取色彩和深度信息,并引入深度加权交叉注意力融合模块,动态调整特征图融合权重。实验结果表明,该方法在伪装物体检测中显著优于其他方法,验证了深度信息的重要性。
DROP是一种用于处理遮挡的人物再识别的方法,通过解耦ReID和人体解析特征,并引入细节保留上采样来处理不同分辨率的特征图,解决两者之间的差异问题。实验结果显示,DROP在Occluded-Duke数据集上达到了76.8%的Rank-1准确率,超过其他两种主流方法。
本研究提出了维度降低知识蒸馏(RdimKD)范式,通过投影矩阵将大网络和小网络的特征图投影到低维子空间,以优化学生网络的训练过程。实证研究表明RdimKD在各种学习任务和不同网络架构中都有效。
我们提出了一种用于句子分类的Squeeze-and-Excitation卷积神经网络(SECNN),通过多个CNN的特征图作为句子表示的不同通道,并结合通道注意机制(SE attention mechanism)学习不同通道特征的注意权重,实现了先进的句子分类性能。
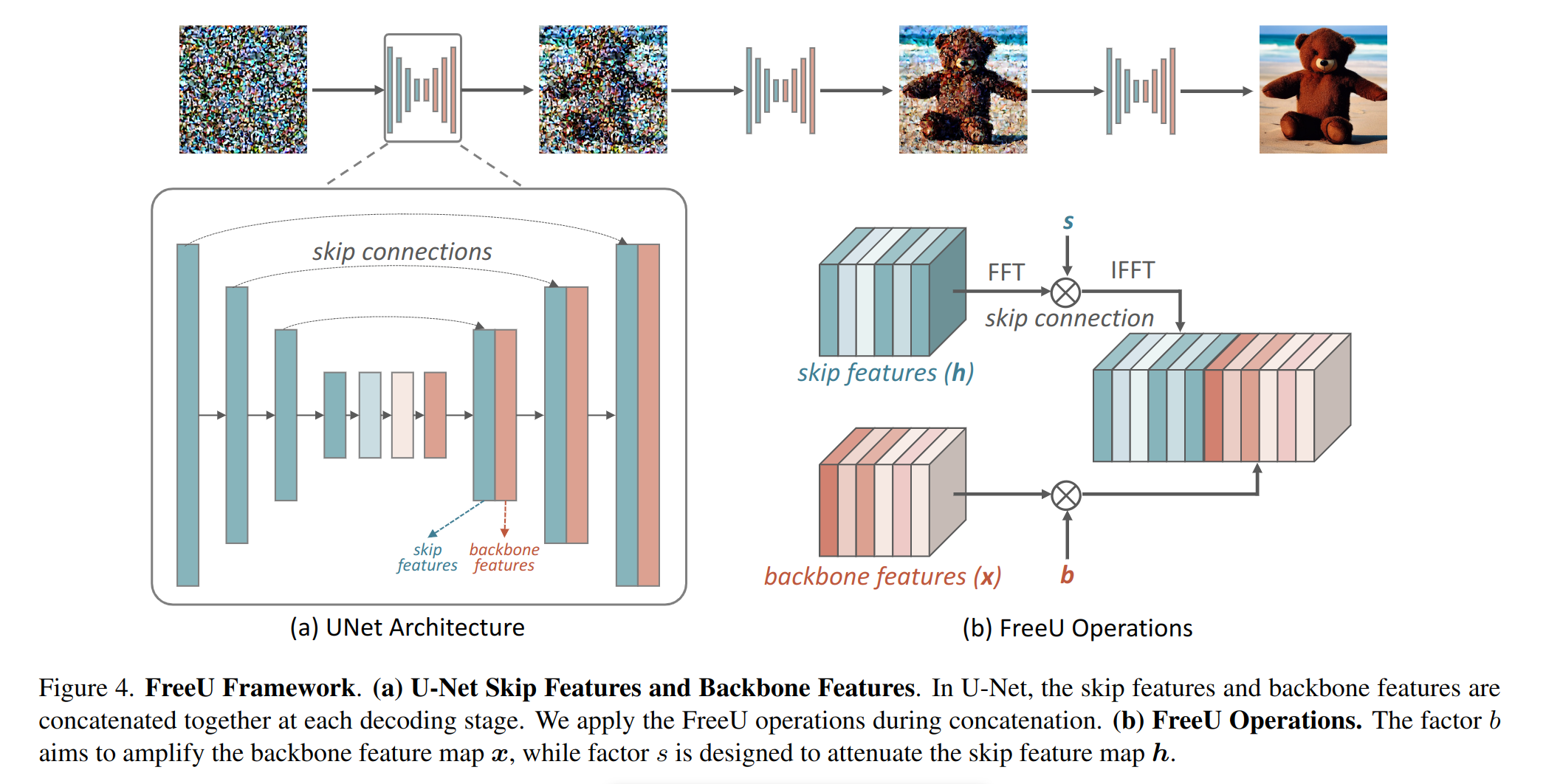
该论文提出了一种改进UNet的方法,通过调整基础连接和跳线连接来提高图像质量,避免了全局应用缩放的不良结果。作者引入了两个标量因子来调整特征图。此外,作者还使用光谱调制来选择性地减少跳过特征的低频分量,以进一步缓解过度平滑纹理问题。
本研究提出了一种新方法,通过融合头部姿势信息和面部定位网络的特征图,改进了面部定位的性能。网络结构使用2D特征图和3D热图表示的多维特征,在双维度网络中实现了鲁棒的面部定位。通过基于知识蒸馏的训练方法,有效地进行密集面部定位。实验评估了预测的面部标记与头部姿势信息之间的相关性,以及面部标记的准确性与头部姿势信息的质量之间的变化。在竞争性性能比较中,证明了所提方法的有效性。
该文介绍了一种基于分割的卷积操作SPConv,用于解决特征图中的模式冗余问题。SPConv将输入特征图分为Representative部分和Uncertain冗余部分,通过相对繁重的计算从代表性部分中提取内在信息,而对不确定冗余部分中的微小隐藏细节进行一些轻量级处理手术。作者还提出了一个无参数特征融合模块来重新校准和融合这两组处理过的特征。消融实验结果表明,配备SPConv的网络在GPU上的准确性和推理时间上始终优于最先进的基线,FLOPs和参数急剧下降。该方法可以轻易与其他网络架构相结合,同时与当前主流模型压缩方法互补,有可能得到更轻量型的模型。
完成下面两步后,将自动完成登录并继续当前操作。