本文介绍了Linux性能监控的适用场景、前提条件及工具,强调在特定情况下不应仅依赖此方案。提供了性能瓶颈分析步骤,包括CPU、内存、磁盘和网络的排查方法,并列出常见瓶颈及优化措施。建议使用Prometheus和Grafana等监控工具进行系统监控。
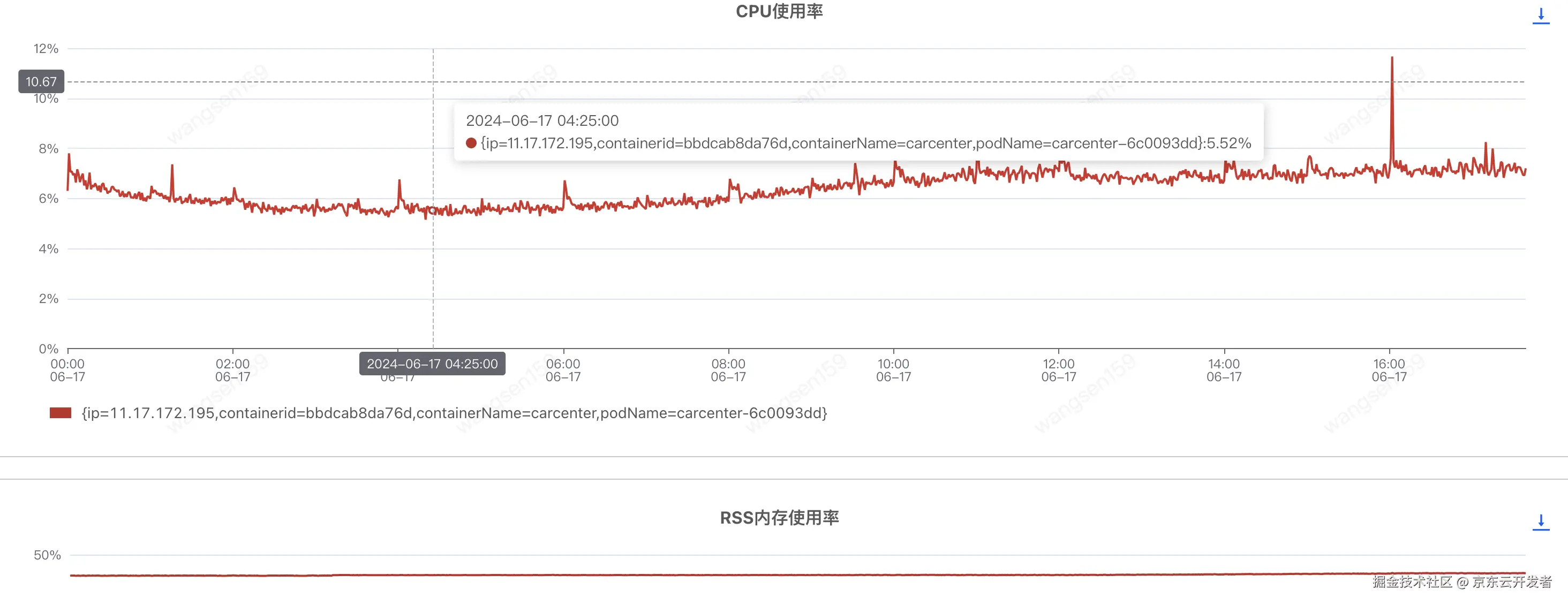
文章分析了调用方A与提供方B之间的耗时差异,识别出网络波动和容器内存使用率为主要瓶颈。通过监控和数据分析,最终通过调整内存和扩容等措施解决了耗时不一致的问题。
完成下面两步后,将自动完成登录并继续当前操作。