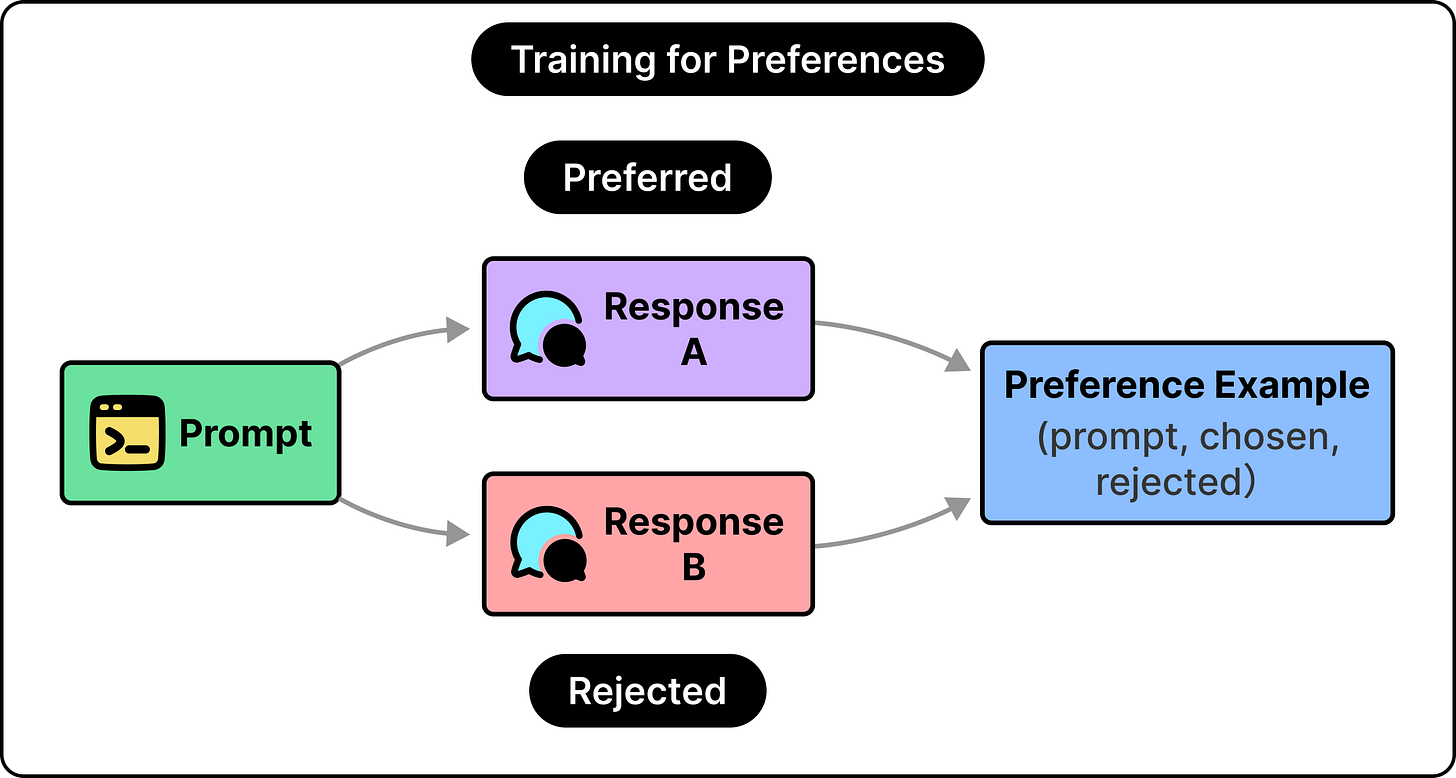
本文探讨了大型语言模型(LLMs)如何通过人类反馈学习,比较了强化学习(RLHF)和直接偏好优化(DPO)两种方法。模型首先通过预训练学习语言和知识,然后通过监督微调学习遵循指令,最后通过比较学习偏好。RLHF通过训练奖励模型并优化,而DPO则简化为单一步骤。两者都依赖于人类判断的信号,但可能导致模型产生迎合性回答。对于可验证的任务,使用可验证奖励可以避免这些问题。
本文探讨了大模型对齐的流程,包括监督微调(SFT)、奖励模型(RM)和强化学习(RL)。对齐不仅提升了模型对指令的理解能力,还影响推理能力和回答质量。文章介绍了直接偏好优化(DPO)作为一种新方法,简化了训练流程,减少了模型数量,提高了效率。未来研究将关注可验证奖励和长上下文推理,以增强模型的推理能力和应用范围。
本研究提出了一种创新的隐私保护对齐算法DP-AdamW,旨在解决大型语言模型对齐中的隐私问题。在中等隐私预算下,该算法结合直接偏好优化(DPO),使对齐质量提升15%,为隐私保护与对齐效率的平衡提供了实用指导。
本研究提出了一种新的训练范式Pre-DPO,旨在提高直接偏好优化(DPO)的数据利用效率。通过使用指导参考模型,Pre-DPO显著提升了DPO和简单偏好优化(SimPO)的性能,无需外部模型或额外数据。
本文提出了一种名为TIS-DPO的令牌级重要性采样方法,用于直接偏好优化(DPO),旨在提高大语言模型的优化效率。TIS-DPO通过为每个令牌分配基于奖励的重要性权重,优化了数据集的使用。实验结果表明,TIS-DPO在无害性和有用性对齐及摘要任务上显著优于基线方法。
本研究探讨了直接偏好优化(DPO)在大型语言模型对齐中的应用,发现多模型生成的合成偏好数据虽然能提升性能,但也增加了安全风险。相比之下,仅使用自生成响应的模型在对齐安全性上表现更佳。
本研究提出了InCo-DPO方法,解决了直接偏好优化中的离线数据质量和分布偏移问题。通过整合在线与离线数据,动态调整二者的平衡,实验结果表明该方法在多个基准测试中显著提升了模型性能。
本研究提出了一种新颖的两阶段训练方法,通过监督微调和直接偏好优化,提升大型语言模型(LLM)作为评判者的能力。在数据需求量仅为其他方法的2%至40%时,该方法实现了先进性能,显著增强了模型的通用能力,并促进了与人类价值观的对齐。
本研究探讨了链式推理对直接偏好优化(DPO)在文本到SQL应用中的影响。通过增强数据集并注入合成的链式推理,DPO的性能显著提升,表明链式推理对DPO潜力的激发至关重要,为文本到SQL模型的构建提供了重要见解。
本研究探讨了直接偏好优化(DPO)在大型语言模型中的应用,提出了新的优化算法和框架,如HyPO和DiscoPOP,以提高模型性能和效率。研究表明,改进的偏好反馈学习方法显著提升了模型输出质量,同时前缀共享技术有效解决了冗余计算问题,提升了训练效率。
本研究探讨了直接偏好优化(DPO)在降低语言模型毒性方面的机制,发现DPO通过多个神经元群体的综合效应实现毒性降低,其中仅31.8%的降低源于被抑制的毒性神经元。
本研究提出了一种新方法,通过在线学习“Flows”来微调大型语言模型(LLMs),显著提升数学推理任务的性能,采用在线直接偏好优化(DPO)学习。
本文研究大型语言模型(LLMs)与人类偏好对齐的复杂性,提出了一个统一框架,将偏好学习策略分为模型、数据、反馈和算法四个部分。通过直接偏好优化(DPO)和混合偏好优化(MPO),提升了模型对用户偏好的理解和适应性,显著增强了偏好学习能力,并推动了未来的研究方向。
本文提出了TIS-DPO方法,针对大型语言模型中的直接偏好优化(DPO),通过为每个令牌分配基于奖励的权重,提升优化效率。实验结果表明,TIS-DPO在安全性和有用性对齐及摘要任务上显著优于多种基线方法。
直接偏好优化(DPO)是一种有效的调优策略,用于将大型语言模型与人类偏好对齐。本文提出了带有偏移量的DPO(ODPO)方法,显著提高了对齐效果,尤其在偏好数量有限时。研究还探讨了冗长性问题,并提出了Mallows-DPO和MinorDPO等改进方法,以增强模型的稳定性和鲁棒性。
本文提出了RS-DPO方法,通过结合拒绝采样和直接偏好优化,提升大型语言模型的精调效果,超越现有方法。研究探讨了DPO和PPO的算法特性,并提出混合偏好优化(MPO)等新方法,以增强模型对人类偏好的对齐能力,解决对齐问题的挑战。
本文探讨了直接偏好优化(DPO)在大型语言模型对齐中的不足,并提出了多参考模型偏好优化(MRPO)和带有偏移量的DPO(ODPO)等新方法,以提升模型的泛化能力和对齐效果。研究表明,这些新方法在处理偏好数据时表现优越,尤其在数据稀缺情况下,推动了自然语言处理任务的性能提升。
本研究提出了多种改进的直接偏好优化(DPO)方法,以增强对噪声数据的鲁棒性和生成文本的质量。结合分布鲁棒优化(DRO)及新方法如Dr. DPO、Mallows-DPO、fDPO等,研究表明这些方法在强化学习与人类反馈的对齐中表现优越,尤其在处理有限偏好对时,显著提升了模型的性能和稳定性。
本文介绍了一种通过优化推理步骤优先级的迭代方法,以提升大型语言模型(LLM)的推理能力。该方法结合了蒙特卡洛树搜索和直接偏好优化,显著提高了算术和常识推理任务的准确性。同时,研究探讨了推理链与模型性能的关系,并提出了新的合成问答数据集PrOntoQA,展示了在多语言推理中的改进效果。
本文探讨了大型语言模型的优化方法,包括相对偏好优化(RPO)和直接偏好优化(DPO),旨在提高模型对用户偏好的理解和适应性,减少对人类反馈的依赖。研究还介绍了ContraDoc数据集,分析了不同模型在处理自相矛盾信息时的表现,发现GPT-4表现最佳但仍需改进。通过引入约束DPO和可控偏好优化,实现了AI系统的安全性与有用性的平衡。
完成下面两步后,将自动完成登录并继续当前操作。