Knowhere 是 Milvus 的向量索引执行引擎,集成了 Faiss、Hnswlib 和 Annoy 等库,支持软删和多种相似度计算。它通过统一的 VecIndex 接口处理索引构建与查询,优化性能并简化开发流程,同时支持自动 SIMD 选择以提升计算效率。
本文介绍了如何从零开始实现向量搜索。向量搜索通过将查询和文档转换为数值向量,匹配语义而非关键词,从而提高搜索智能性。文章详细讲解了向量表示、相似度计算和检索步骤,并提供了Python实现示例,包括数据集创建、向量转换和余弦相似度计算。最终,读者将掌握向量搜索的基本原理及其应用。
文本嵌入模型将文本转换为数值向量,支持文本相似度计算和信息检索等任务。MTEB排行榜评估了250多个模型,涵盖多语言和多任务,适用于不同领域。选择模型时需考虑任务类型、语言支持和计算资源等因素。
研究表明,余弦相似度在高维对象的相似性测量中可能导致无意义的结果,尤其在深度学习模型中。因此,建议谨慎使用余弦相似度,并提出欧几里得距离和点积等替代方案,以提高相似度计算的可靠性。
本文介绍了语义匹配的概念及其在自然语言处理中的应用。与传统的精确匹配方法不同,语义匹配关注词语的意义和上下文。利用Python及相关库(如KeyBERT和SentenceTransformer),可以提取关键词并计算与特定短语(如“避孕”)的相似度,从而有效找到相关内容。
VecSpark是一个基于PySpark的库,旨在高效处理大规模向量嵌入。它支持多种相似度计算方法,并能将大文本分块以便存储和处理,适用于大规模NLP和分析应用。
本文介绍了1bit量化embedding模型,强调其在相似度计算中的优势,具有32倍的压缩率和25倍的检索速度,同时保持95%的检索准确率。此外,提到Sentence Transformers库支持超过1万个embedding模型。
自然语言处理(NLP)是计算机科学与人工智能的重要领域,旨在实现人与计算机的自然语言交流。文本聚类是NLP的一个应用,通过相似度将文本自动归类。传统的聚类方法如K-Means和层次聚类在特征选择和相似度度量上存在局限性,而深度学习方法通过文本表示学习和相似度计算显著提升了聚类效果。结合大语言模型进行聚类分析,展示了不同方法的优缺点。
本文介绍了多种针对抽象意义表示(AMR)的新方法和度量标准,如 S$^2$match、SMARAGD 和 SEMBLEU。这些方法在 AMR 图的相似度计算、解析准确性和多语言句子嵌入性能方面表现出色,显示了在语义评估和生成文本质量评估中的潜力。研究表明,这些新指标和算法在控制偏差和提高准确性方面优于传统方法。
句子嵌入是句子的向量表示,可以通过池化方法计算。池化是一种常用方法,通过BERT模型的[CLS]标记嵌入来表示整个句子。句子嵌入可用于文本分类和相似度计算等任务。使用句子转换器库可以获得更高质量的嵌入。选择合适的模型可根据任务需求和性能指标评估。嵌入的生态系统包括工具、数据库和相关研究。
本文介绍了文本向量化的传统做法和现成的向量化大模型,以及如何计算向量数据的相似度,包括余弦相似度和欧式距离算法。同时,介绍了t-SNE算法的应用,可以将向量数据可视化,最后讲述了如何应用在相似度检测上。
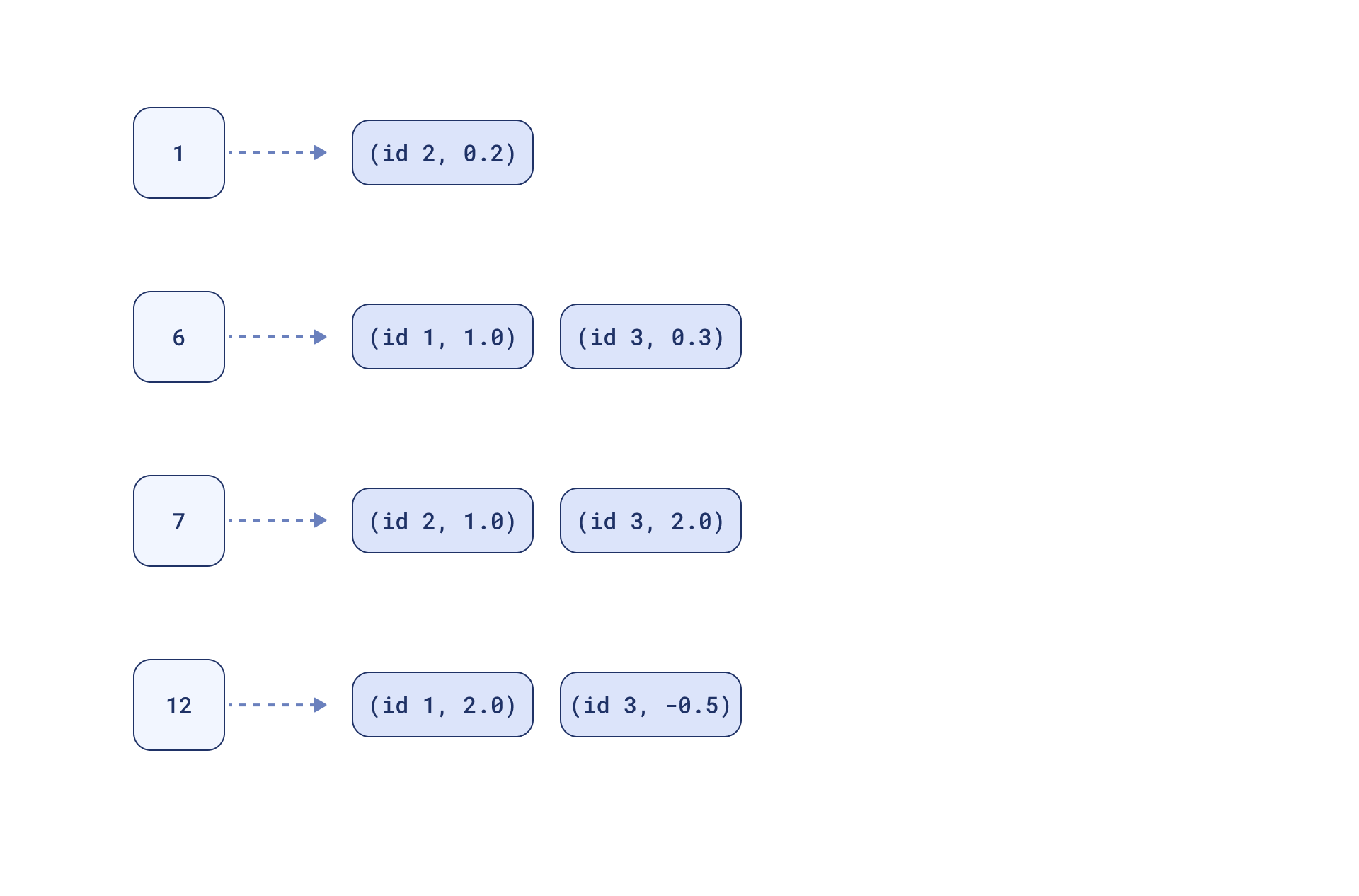
稀疏向量是高维向量,主要用于关键词搜索和推荐系统。它们在少数维度上有值,其他维度为零。通过倒排索引,可以高效存储和检索稀疏向量,快速找到相似向量。Qdrant支持稀疏向量的配置和存储,使用点积计算相似度。
完成下面两步后,将自动完成登录并继续当前操作。