随着数据集规模的增大,训练大型人工智能模型面临不同社群价值观的风险。研究表明,使用过滤后的网络数据也能训练出性能良好的语言模型。文章探讨了稠密检索模型的缩放规律,提出了对比对数似然作为评估指标,并通过实验验证了其性能与模型大小和注释数量的关系。此外,研究还提出了在数据稀缺情况下优化模型的方法,强调高质量数据的重要性。
本文提出了信息检索和自然语言处理的概念框架,整合了稠密和稀疏检索方法,分成逻辑评分模型和物理检索模型。作者提出了度量器和比较函数,计算查询-文档分数,并分析了密集与稀疏表征和监督与无监督方法的影响。提供了一个研究路线图,为未来工作提供方向。
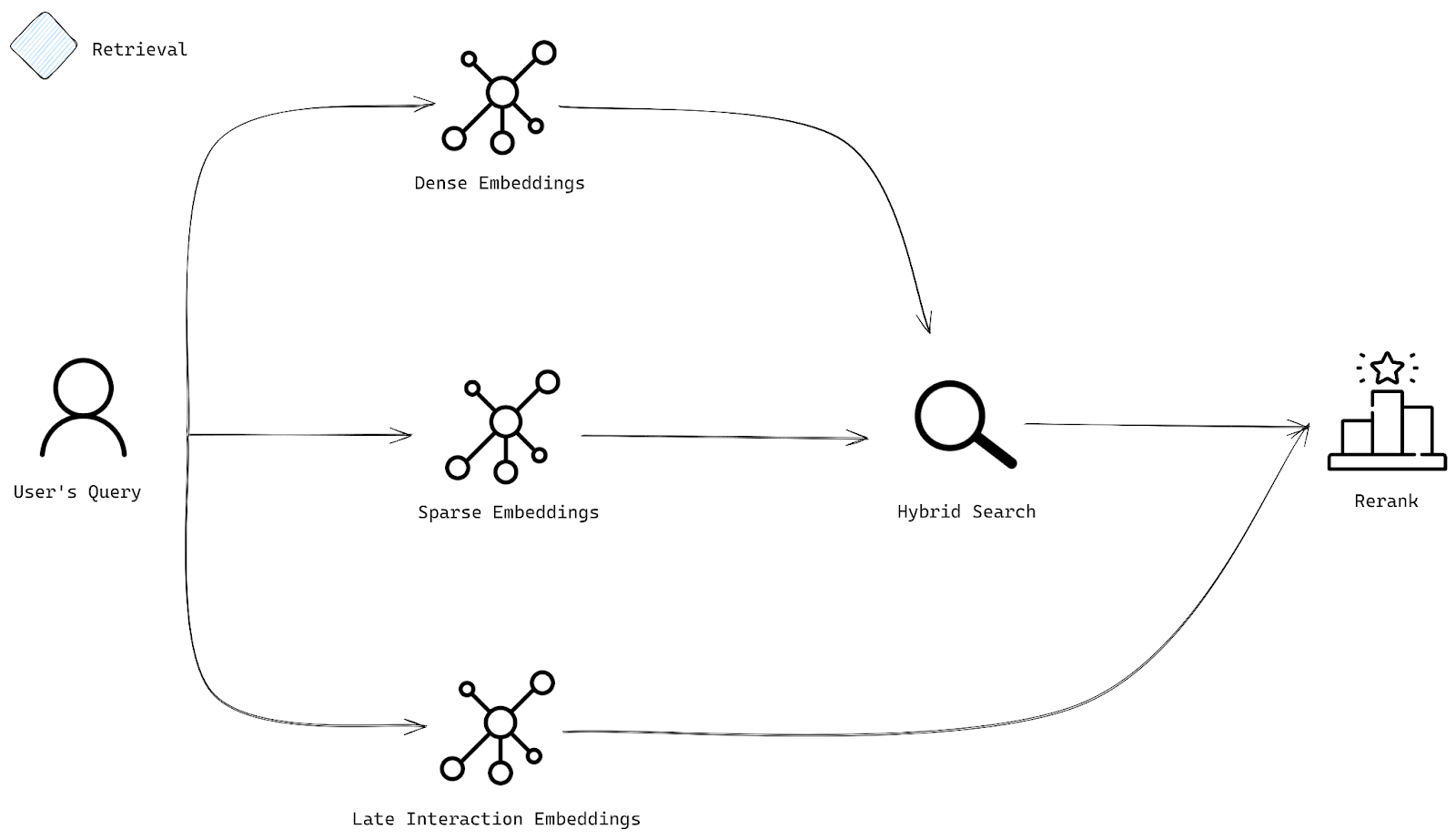
Qdrant混合搜索结合稠密和稀疏检索,通过ColBERT重排序提升搜索结果相关性。本文介绍如何在Qdrant中实现混合搜索,利用不同类型的嵌入创建高效搜索系统,确保最终结果符合用户意图,提升搜索体验。
完成下面两步后,将自动完成登录并继续当前操作。