蚂蚁灵波发布了LingBot-VLA 2.0,这是一个开源的视觉-语言-动作模型,专注于复杂物理任务。该模型基于60000小时的真实物理数据,适用于多种机器人构型和任务,尤其在家务等领域表现优异,具备更强的空间理解和未来预测能力,旨在推动机器人技术的通用化和在真实环境中的应用效果。
乐动机器人专注于提升机器人对物理环境的感知能力,利用多模态传感器和AI模型将复杂现实数据转化为可供学习的信息,推动机器人在家庭和酒店等场景的应用。公司致力于构建持续供给真实世界数据的系统,以应对未来机器人行业的挑战和需求。
京东开源的多模态基础模型JoyAI-Image-Edit支持文生图、图像理解和指令引导的图像编辑,具备像素级精细化编辑和空间感知能力,解决了理解与生成之间的“空间断层”。该模型在电商、具身智能和3D重建等领域应用广泛,显著提升创意验证效率。
京东开源的多模态基础模型JoyAI-Image-Edit支持文生图、图像理解和指令引导的图像编辑,具备像素级精细化编辑和空间感知能力,解决了理解与生成之间的“空间断层”。该模型在电商、具身智能和3D重建等领域广泛应用,提升了创意验证效率。
京东探索研究院开源了多模态基础模型JoyAI-Image-Edit,支持文生图、图像理解和指令引导的图像编辑。该模型实现了像素级精细化编辑和空间智能,解决了理解与生成之间的“空间断层”,在空间理解和编辑能力上达到世界一流水平,广泛应用于电商、具身智能和3D重建等领域,显著提升创意验证效率。
京东开源的多模态基础模型JoyAI-Image-Edit支持文生图、图像理解和指令引导的图像编辑,具备像素级精细化编辑和空间理解能力,解决了理解与生成之间的“空间断层”。该模型在电商、具身智能和3D重建等领域表现出色,开发者可在HuggingFace或Github获取。
GLM-5.1模型上线,编程能力较前代提升近10分,接近全球最强模型Opus 4.6。用户反馈积极,支持多平台接入,已售罄。实测显示其在空间理解和动态补全方面表现优异,适合复杂任务。
Google发布了新一代图像生成模型Nano Banana 2,提升了图像质量和理解能力。该模型接入丰富的知识库,能够更好地理解空间和比例,生成的图像更加自然和准确。用户可以以低成本生成高质量图像,整体体验显著改善。同时,Google加强了防伪技术,以应对假图问题。
商汤日日新发布的SenseNova-SI系列开源模型在空间智能领域取得突破,评测表现超越GPT-5等顶尖模型,显著提升空间理解能力,为AI在物理世界的应用奠定基础。
Pim de Witte创立了AI实验室General Intuition,获得1.337亿美元融资,利用视频游戏数据训练AI,开发具有空间理解能力的模型,应用于无人机和机器人等领域。尽管面临竞争和风险,De Witte认为游戏数据将促进AI在现实世界的应用。
元戎推出的VLA(视觉语言动作)模型,标志着智能辅助驾驶的新阶段,具备更强的语言和空间理解能力,支持多芯片平台,未来将应用于Robotaxi和机器人。该模型基于GPT架构,提升推理能力,预计将推动行业发展。
智源研究院推出RoboBrain 2.0和RoboOS 2.0,前者在空间理解、时间建模和长链推理方面取得突破,后者为具身智能提供SaaS开源框架,支持多智能体协作,推动机器人向群体智能转型。
UCLA与谷歌合作研发的3DLLM-MEM模型首次赋予AI在复杂3D环境中长时记忆能力,成功率超基线16.5%。该模型通过双记忆架构和动态更新机制,显著提升了AI的空间理解和任务执行能力。
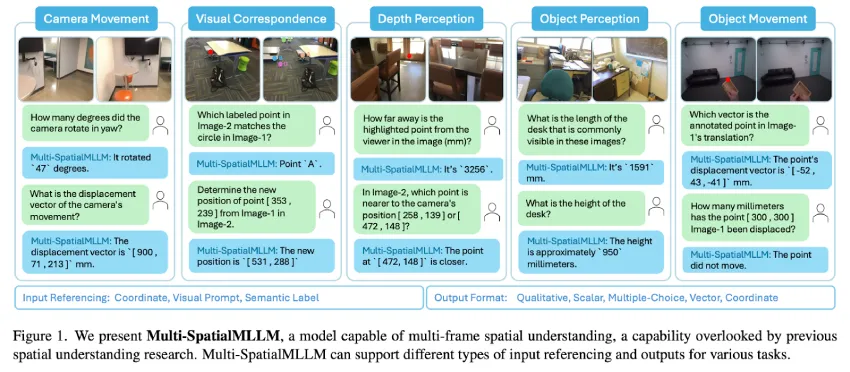
研究者提出MultiSPA数据集和Multi-SpatialMLLM模型,以解决多模态大型语言模型在空间理解方面的局限,显著提升了多帧空间推理能力,准确率达到80-90%。该模型在多任务学习中表现优异,填补了研究空白,具有广泛的应用潜力。
谷歌DeepMind推出Gemini Robotics,结合AI与物理世界,提升机器人在复杂任务中的表现。新模型具备通用性、互动性和灵活性,能够适应不同环境并执行精细操作,同时增强空间理解,提高机器人安全性与智能。
谷歌DeepMind推出基于Gemini 2.0的Gemini Robotics和Gemini Robotics-ER模型,旨在提升机器人在现实世界中的应用能力。Gemini Robotics具备先进的视觉-语言-行动能力,能够适应多种环境并执行复杂任务;而Gemini Robotics-ER专注于空间理解,增强机器人控制能力。这两者的结合提升了机器人的互动性和灵活性,推动了安全性研究,助力下一代人形机器人发展。
本文提出了SpatialVLA模型,旨在解决机器人操作中的空间理解问题。通过引入Ego3D位置编码和自适应动作网格,提升机器人在多任务和新环境中的适应能力。实验结果表明,该模型在复杂动作轨迹推理和多任务学习方面表现优异。
本研究提出了一种网格叠加方法,通过在输入图像上添加9x9黑色网格,增强多模态模型的空间理解能力。实验结果表明,该方法显著提高了空间定位的准确性,适用于机器人操作、医学成像和自主导航等领域。
本文提出了一种视觉-时间上下文提示方法,以解决视觉语言模型在开放世界环境中的决策挑战。该方法利用物体分割信息,帮助低级策略基于视觉观察进行预测,从而提升空间理解能力。
完成下面两步后,将自动完成登录并继续当前操作。