本文介绍了CVPR 2025的CV4Metaverse研讨会上接受的研究,提出了SCOPE数据集和iSQoE模型,用于评估立体视觉体验质量,旨在克服现有方法的局限性。
本文介绍了一种嵌入无人机的立体视觉系统,能够实时评估道路状况,提升交通安全。研究提出了多种目标检测算法和模型,如NDFT、JointYODNet和DAPONet,优化了小目标检测和道路损坏识别的性能,展现出高精度和鲁棒性,适用于实时应用。
本文介绍了一种新方法,通过结合单视图和多视图深度,从动态场景图像中合成任意视角和时间的图像。研究探讨了深度学习在立体视觉中的应用,提出了新型网络和神经渲染方法,并展示了在新视角合成和几何建模中的最新成果。
本文介绍了2016年至2024年间多种基于立体视觉和单目图像的3D目标检测方法。这些方法通过优化能量函数和引入新模型及数据集,显著提高了自动驾驶领域的检测精度。MonoGAE框架结合地面几何信息,增强了对道路场景的感知能力。
本文介绍了一种基于立体视觉的障碍物检测方法,能够在自动驾驶中有效识别小障碍物,且不依赖全局道路模型。研究评估了多模态3D物体检测算法的鲁棒性和准确性,提出了无监督对抗领域自适应方法,以解决不同环境下的性能下降问题,并引入新的分类系统以提升文献的清晰度。
该研究综述了深度学习在立体视觉和图像深度估计中的应用,分析了单目和双目图像深度估计的最新进展、算法及其优缺点,并提出了提高模型准确性的新方法,强调了实时立体匹配在自动驾驶等领域的重要性。
该研究提出了一种基于关键点的物体位姿估计方法,结合RGB图像和立体视觉技术,显著提高了6D姿态估计的准确性。通过解耦姿态和尺寸估计,优化了算法性能,并在多个数据集上验证了其有效性。
本文介绍了一种新的立体事件驱动视频帧插值网络(SEVFI-Net),通过特征聚合模块解决视差问题,提升光流和视差估计的准确性。研究构建了立体视觉采集系统,并收集了新的数据集(SEID)。实验结果表明,SEVFI-Net 在多个数据集上优于现有方法,显著提高了视频插帧的质量和效率。
该研究提出了一种名为Gated Stereo的深度估计技术,结合了单目和立体深度预测,显著提高了深度估计的准确性,尤其在长距离场景中表现优异。该方法通过融合多种传感器数据,克服了现有技术的局限性,适用于自动驾驶等领域。
本文提出了一种新方法NAFSSR,通过交叉注意模块在立体视觉场景中融合特征,提升图像超分辨率。该方法在多个数据集上表现优异,并在NTIRE 2022挑战中获第一名。
该研究综述了深度学习在立体视觉和图像深度估计中的应用,分析了常见流程、优缺点及未来发展方向。提出了多种方法,如半监督深度估计、自监督几何感知框架和新型深度管道,强调了在不同数据集上的优越性能和研究趋势。
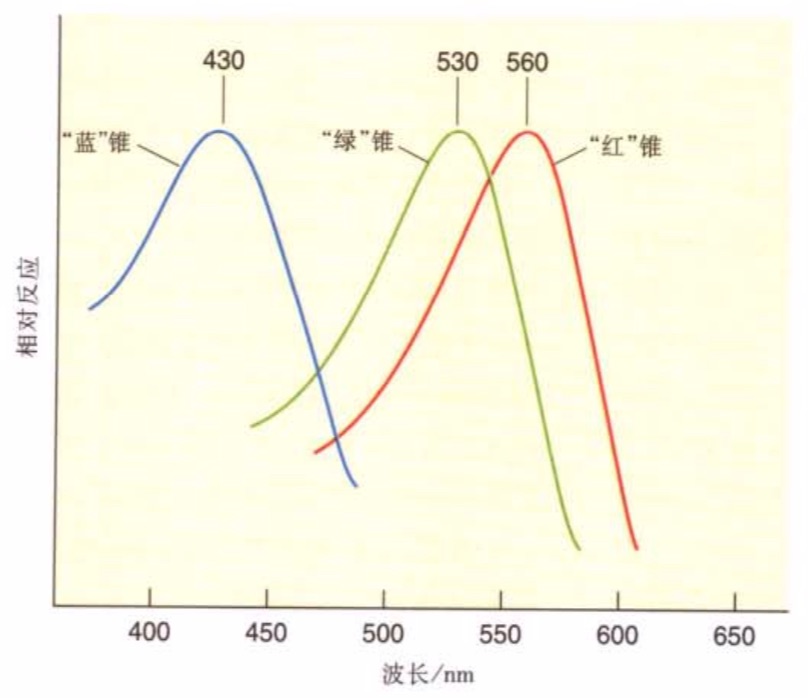
人眼的视觉系统类似于相机,通过晶状体和睫状肌调节焦距。视网膜将光信号转化为电信号,主要由光感受器和神经节细胞组成。视锥细胞负责颜色感知,视杆细胞在暗环境中更敏感。大脑根据双眼图像差异构建立体视觉,视觉过程复杂,涉及光的翻译与信息解释。
完成下面两步后,将自动完成登录并继续当前操作。