CuTe中的local_tile函数用于在线程块级别将张量划分为小块,并根据线程块坐标进行切片。与local_partition相比,local_tile更易于理解,且无需复杂的数学运算。它通过inner_partition实现,适合将较大问题分解为多个小问题,从而简化坐标计算。
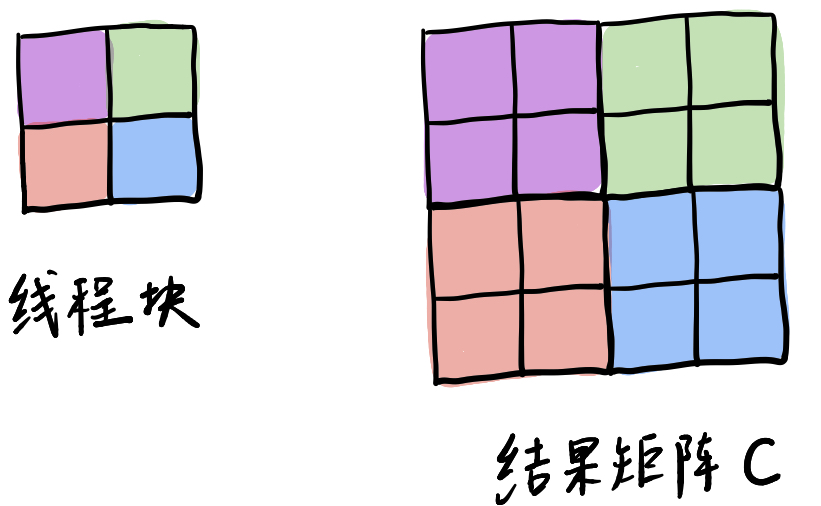
CUDA中通过调整线程块与结果矩阵的映射关系,实现一对多的映射,优化矩阵相乘的stride技巧,从而减少线程块数量,提高计算效率。最佳stride值需通过实验确定。
完成下面两步后,将自动完成登录并继续当前操作。