

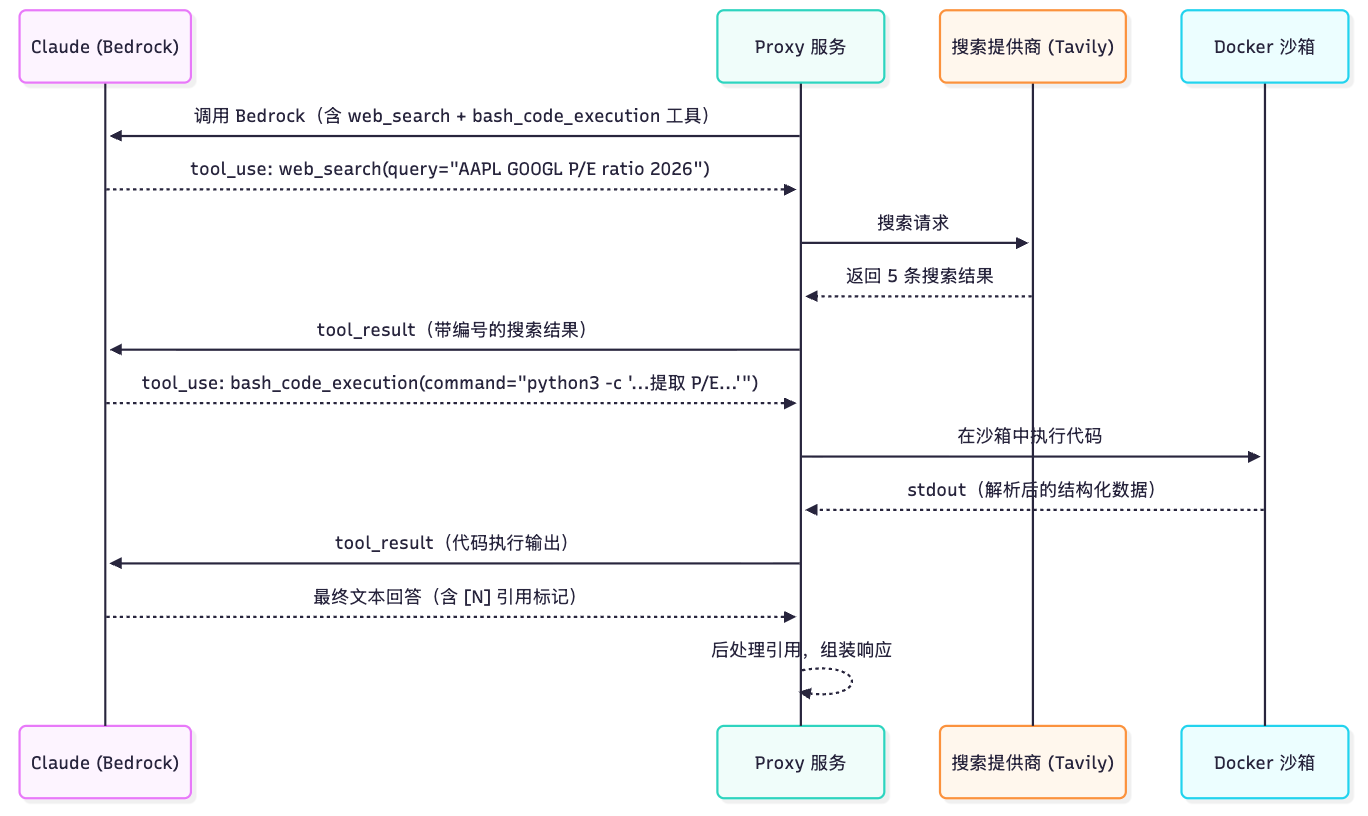
利用 Amazon Bedrock AgentCore 快速为您的 Agent 接入联网搜索和网页浏览
亚马逊AWS官方博客
·

构建真正有效的专业网页抓取工具
freeCodeCamp.org
·



被低估的 .NET 开源项目:AngleSharp,优雅的 HTML 解析神器
dotNET跨平台
·


数据科学项目的十大免费API提供商
KDnuggets
·

通过Bright Data和LlamaIndex为AI代理提供网络访问
Blog on LlamaIndex
·

与Oxylabs和LlamaIndex构建更智能的AI代理
Blog on LlamaIndex
·

GoLogin:开发者的多账户浏览器管理与网页抓取指南
DEV Community
·

什么是数据抓取?详细指南
DEV Community
·

轻松获取AP新闻数据的方法
DEV Community
·

AI应用中的文档加载、解析与清理
DEV Community
·

Python中使用Parsel的终极网页抓取指南
DEV Community
·

网页抓取:数据科学中的关键工具
DEV Community
·

如何在AWS Lambda上运行Puppeteer
DEV Community
·

我如何在1小时内用Python学习网页抓取
DEV Community
·

TikTok API综合指南
DEV Community
·
