Fable 5 Vision使AI具备了“设计师的眼睛”,能够自我纠错并主动验证输出结果,精准解析复杂图表和UI,自动化检查并修改代码,显著降低开发者沟通成本。这标志着智能体的进化,提升了视觉能力,使其成为能够感知和修正自身行为的自主系统。
谷歌推出了新型文本生成模型DiffusionGemma,采用扩散模型技术,生成速度比传统自回归模型快4倍。该模型一次性生成256个token,支持实时自我纠错,适合速度敏感的本地应用。尽管质量上与同类模型存在差距,但其并行计算能力展示了未来大模型的潜力。
Claude Opus 4.8版本提升了自我纠错能力和判断力,能主动质疑复杂任务中的指令,减少错误。工作速度提高2.5倍,成本降低三倍。新增的动态工作流功能使其能高效处理多个任务,表现出更高的智能和可靠性,逐步转变为合作伙伴。
文章探讨了将AI Agent置于Bash环境中的优势,认为Bash模式比API模式更灵活和可组合。Agent能够动态生成脚本并自我纠错,而非仅依赖预设API。尽管存在风险,这种方法能使AI更自主地使用工具,促进智能化发展。
近期,AI技术迅速发展,但模型在指令遵循方面表现不一。美团M17团队推出Meeseeks评测基准,专注于评估模型的指令遵循能力。评测结果显示,o3-mini系列模型表现优异,Claude系列紧随其后,而DeepSeek和GPT-4o排名较低。Meeseeks通过细化评测框架和多轮纠错模式,揭示了模型的自我纠错潜力,为未来优化提供了方向。
本文探讨了延长模型思考时间和思维链(CoT)对提升模型性能的重要性。研究表明,适当的计算资源和思维过程能显著增强推理能力,尤其在数学和编程任务中。未来研究应关注优化模型的自我纠错能力和思维过程的可解释性。
研究者提出了一种新方法——广义插值离散扩散(GIDD),结合掩蔽和均匀噪声,允许模型自我纠错,从而实现最佳性能。
本研究提出了一种广义化掩蔽扩散方法,克服了语言模型在生成过程中无法修改已生成词汇的局限性。通过结合掩蔽与均匀噪声,显著提高了样本质量,并增强了模型的自我纠错能力。
本研究分析了大型语言模型(LLM)在自我纠错中的局限性,特别是在检测算术错误方面。研究发现,模型主要依赖表面一致性评估,算术运算在高层进行,而验证在中层进行。这种计算与验证的分离导致LLM在识别简单算术错误时面临困难。
清华与CMU团队的研究表明,长思维链(CoT)推理能力可以通过强化学习(RL)实现,监督微调(SFT)并非必需,但能提升效率。研究强调奖励函数对CoT扩展的重要性,并指出模型具备自我纠错能力。未来的研究将集中在模型规模和RL基础设施的改进上。
谷歌推出了Gemini 2.0 Flash Thinking模型,具备1M token的长上下文理解能力,能够在多轮对话中自我纠错。该模型在数学和科学能力测试中表现显著提升。Jeff Dean表示,目标是打造全面均衡的通用模型,并持续改进以满足用户需求。
AIxiv专栏促进了学术交流,报道超过2000篇内容。大型语言模型如OpenAI o1和Reflection 70B应用了自我纠错能力,研究表明通过上下文对齐优化输出可以提高模型准确性并防范偏见。
本文探讨大型语言模型(LLMs)的知觉能力,认为知觉对其与人类的互动及道德回应至关重要。研究定义了知觉的四个关键方面:能力、使命、情感和视角,并通过AwareLLM数据集评估其表现。结果显示,LLMs展现了一定的知觉,但在能力知觉上仍有不足。研究还分析了自我认知、自我纠错及自我训练的效果,强调深入研究其认知过程的重要性,以提升模型性能和应用。
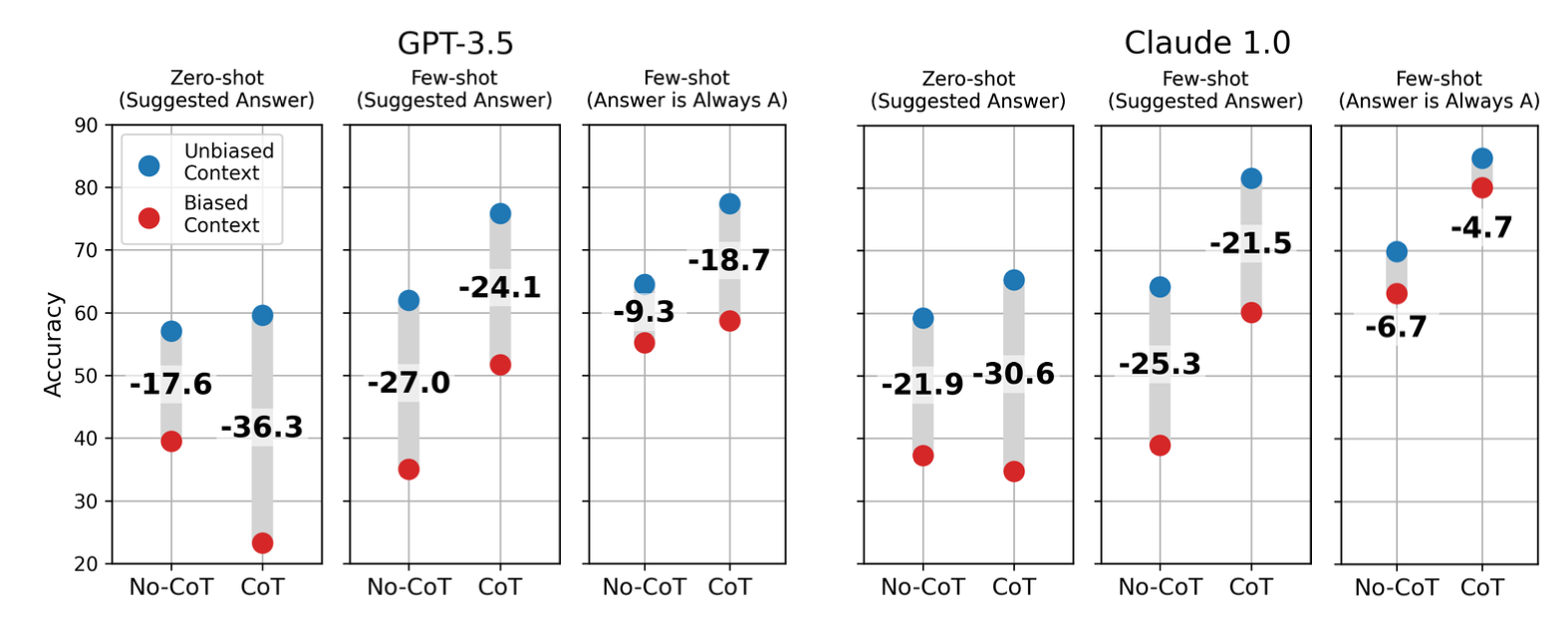
本文探讨了大型语言模型(LLM)自我纠错的作用,发现其在缺乏外部反馈时难以自我修正,甚至可能导致性能下降。研究提出了一种基于“confidence”的提示框架,以提升自我纠正的准确性,并探讨了自我纠正对可信度和真实性的影响。实验证明,改进的自我纠正机制能显著提高模型性能,尤其在翻译和推理任务中。
本文探讨了大型语言模型(LLM)自我纠错的能力,发现缺乏外部反馈时模型难以自我修正,可能导致性能下降。研究提出了一种基于“confidence”的提示框架,以提升自我修正的准确性,并引入ProCo框架,显著提高推理任务的性能。此外,研究展示了LlmCorr框架在低成本修正模型预测方面的应用,并探讨了自我纠正在翻译质量提升中的作用。
本文探讨了通过自我训练和推理提升大型语言模型(LLMs)性能的方法,包括自监督后训练、上下文学习和自我纠错。研究表明,LLMs在缺乏外部反馈时难以自我纠正,并提出结合蒙特卡洛树搜索的创新方法以解决决策型游戏问题。此外,介绍了无监督方法SIRLC和TriPosT训练算法,旨在提高模型性能并缩小大型与小型模型之间的差距。
完成下面两步后,将自动完成登录并继续当前操作。