OpenProtein.AI由Tristan Bepler和前MIT教授Tim Lu创立,提供无代码平台,帮助科学家进行蛋白质工程。该平台使研究人员能够设计蛋白质、预测其结构与功能,并加速药物开发。OpenProtein.AI的工具对学术界免费,旨在让更多生物学家接触先进的AI技术,推动新疗法的研发。
随着人工智能的发展,蛋白质工程进入AI辅助设计阶段。为降低使用门槛,上海交通大学开发了VenusFactory平台,简化数据检索和模型训练,支持无代码操作,促进生物科学研究。该平台整合多个数据库,提供核心任务评测,助力科学家高效研究。
本研究提出了一种新型蛋白质语言模型Prot42,旨在解决传统蛋白质工程的复杂性和资源消耗问题。Prot42能够生成高亲和力的蛋白质结合剂,并处理长达8192个氨基酸的序列,显著提升计算蛋白设计能力。
研究者提出了多模态框架ProteinDT,通过对齐蛋白质序列与文本描述,辅助蛋白质设计。实验表明,该框架在多项任务中表现优异,推动了蛋白质工程的发展。
本研究探讨神经符号人工智能(NeSy)在医疗领域的应用,特别是在药物发现和蛋白质工程中的潜力。NeSy结合符号推理与深度学习,能够处理复杂医疗数据并提供解释能力,提出了改进策略和未来实验建议。
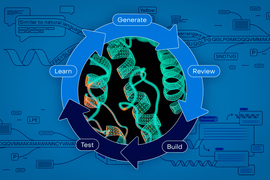
VenusFactory是一个统一的蛋白质工程数据检索与语言模型微调平台,旨在解决数据收集和任务基准测试的挑战,促进计算机科学与生物学的跨学科合作。
上海交通大学洪亮教授团队推出了VenusMutHub,这是首个针对真实应用场景的蛋白质突变小样本数据集,并提出了评测标准。该研究克服了现有高通量数据集的局限性,为蛋白质工程提供实用指导,推动了蛋白质功能预测的发展。
浙江大学研究人员开发了基于蛋白质语言模型的自动进化平台PLMeAE,结合机器学习与自动化生物工厂,显著提高了蛋白质工程的速度和准确性,优化了设计与测试流程,推动了工业应用的发展。
研究团队提出了一种AI辅助的酶热稳定性工程策略,仅需两轮设计,成功获得50个组合突变体,稳定性设计成功率达100%。最佳突变体13M4的Tm提高10.19℃,半衰期增加655倍,催化活性保持不变,显著提升了蛋白质工程效率。
合成生物学结合生物学、工程学和计算机科学,旨在设计新生物系统。人工智能(AI)提升了设计和优化能力,但也带来了测试和验证的挑战。文章探讨了AI在基因设计、蛋白质工程和代谢途径优化中的应用,以及在复杂生物系统中测试AI的困难,如数据质量和伦理问题。有效的测试方法包括实验验证和模拟。未来需发展标准化测试框架和实时测试能力,以确保AI系统的可靠性和伦理合规性。
近年来,产学研用结合在AI领域愈发重要。洪亮教授指出,科研应关注实际问题,AI在蛋白质工程等领域取得了重要突破,推动产业化。团队合作与跨学科研究是成功的关键,未来需继续探索AI与科学的结合。
浙江大学团队开发了去噪蛋白质语言模型(DePLM),通过去除无关进化信息,提高蛋白质优化和泛化能力。DePLM在突变效应预测中优于现有模型,并能有效泛化到新蛋白质。研究结合进化信息与实验数据,推动蛋白质工程发展。
在「Meet AI4S」直播中,周子宜博士介绍了蛋白质语言模型(PLM)在蛋白质工程中的应用。PLM通过建模蛋白质序列的共进化信息来预测突变的适应性,并生成蛋白质。研究重点包括检索增强型、多模态PLM和小样本学习方法FSFP。FSFP通过排序学习、LoRA和元学习提升性能,适用于不同PLM。未来方向包括AI辅助定向进化中的主动学习策略。
浙江大学的研究团队提出了一种名为InstructProtein的模型,通过知识指令对齐蛋白质语言和人类语言,实现了双向生成能力。该模型在蛋白质序列理解和设计方面优于现有的大语言模型。研究人员使用UniProtKB构建了蛋白质知识图谱,并通过指令数据集进行模型微调。InstructProtein能够准确预测蛋白质的功能和位置,对蛋白质工程和药物发现具有重要意义。该研究为蛋白质大模型的发展提供了新的思路和方法。
本研究提出多种基于扩散模型的蛋白质设计方法,旨在生成高质量、特定功能的蛋白质结构。通过结合生物信息和图神经网络,提升了生成效率和结构稳定性,展示了在蛋白质工程领域的应用潜力。
上海交通大学洪亮课题组研发了一种名为PROTLGN的微环境感知图神经网络,能够从蛋白质三维结构中学习并预测有益的氨基酸突变位点,指导蛋白质设计。PROTLGN具有更高的效率和准确性,可用于突变预测、荧光蛋白优化、VHH抗体设计和Ago蛋白突变等方面。此外,PROTLGN还能预测蛋白质的亚细胞定位。
本文探讨了机器学习技术在预测分子离子化能量和基因组测序中的应用。研究表明,优化训练集和模型可以显著提高预测准确性。此外,机器学习指导的定向进化方法在蛋白质工程中表现优异,成功创造出高催化选择性的变异体。
完成下面两步后,将自动完成登录并继续当前操作。