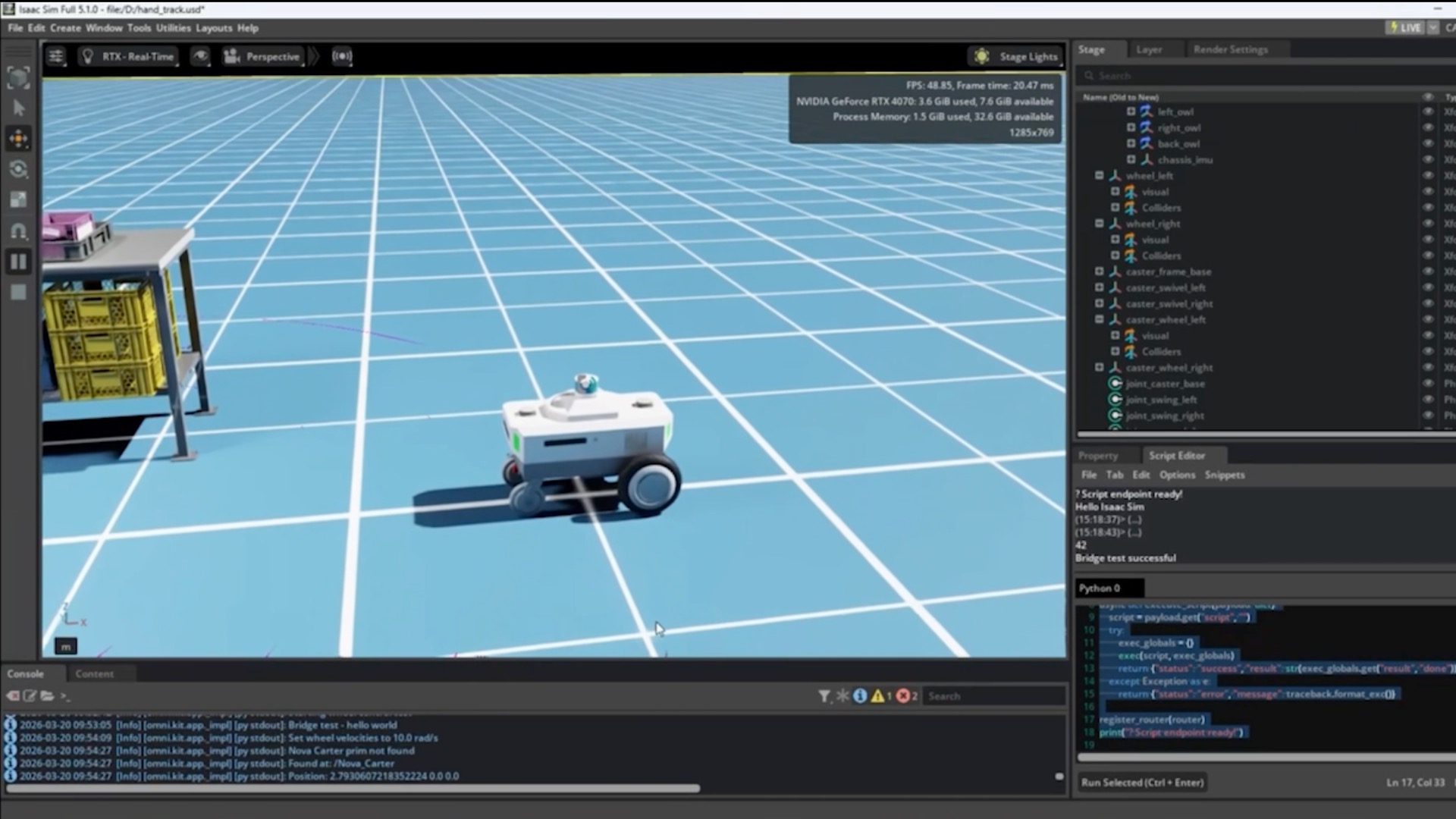
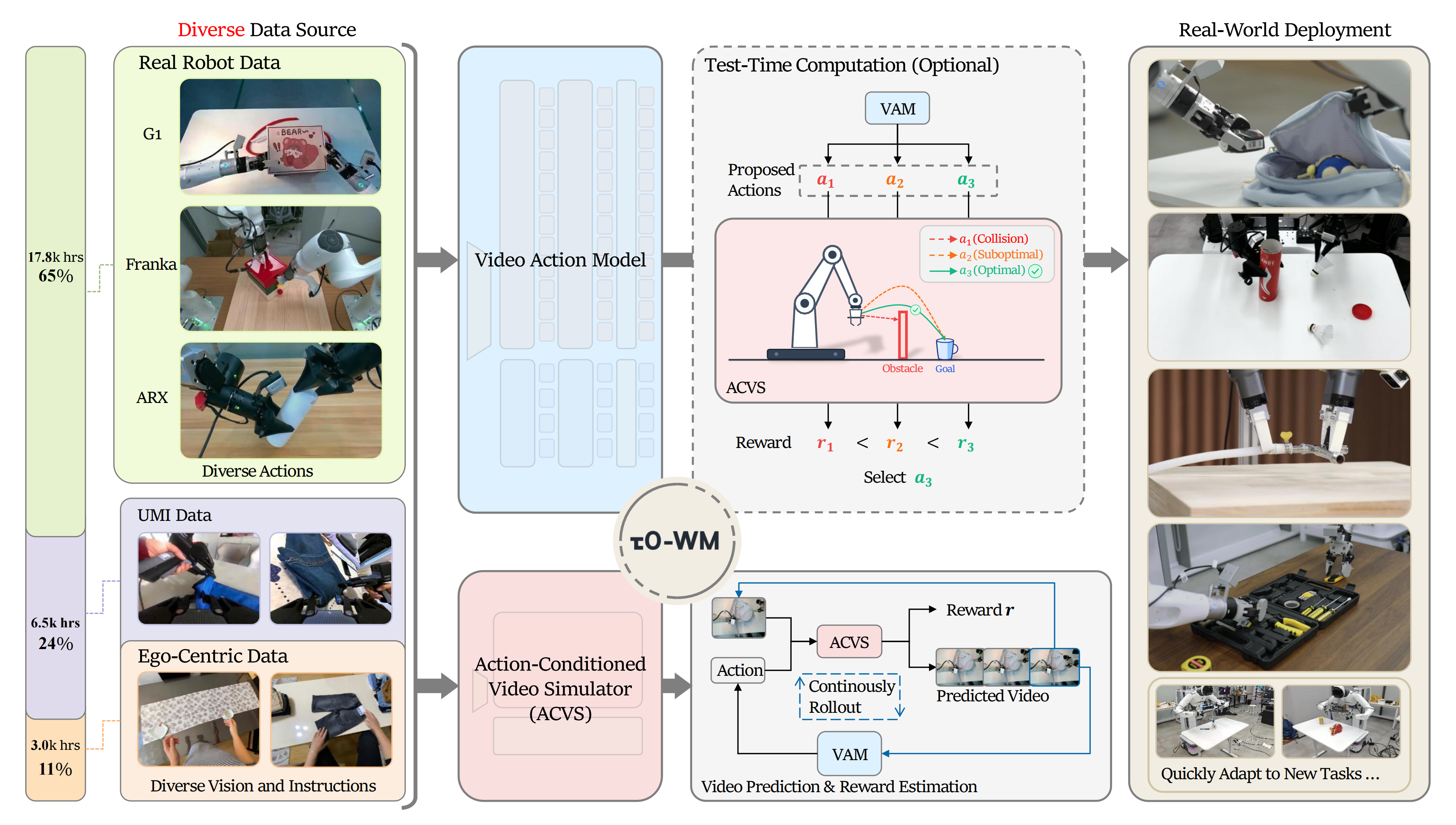
进入全宇宙:通过合成数据和微调提高视觉AI代理准确性的三种工作流程
NVIDIA Blog
·

《星际狐狸》是Switch 2上最令人印象深刻的视觉展示
The Verge
·


详解墨水屏对接LS26视觉语音开发板(Arcs-mini )
分享AI芯片开发经验
·
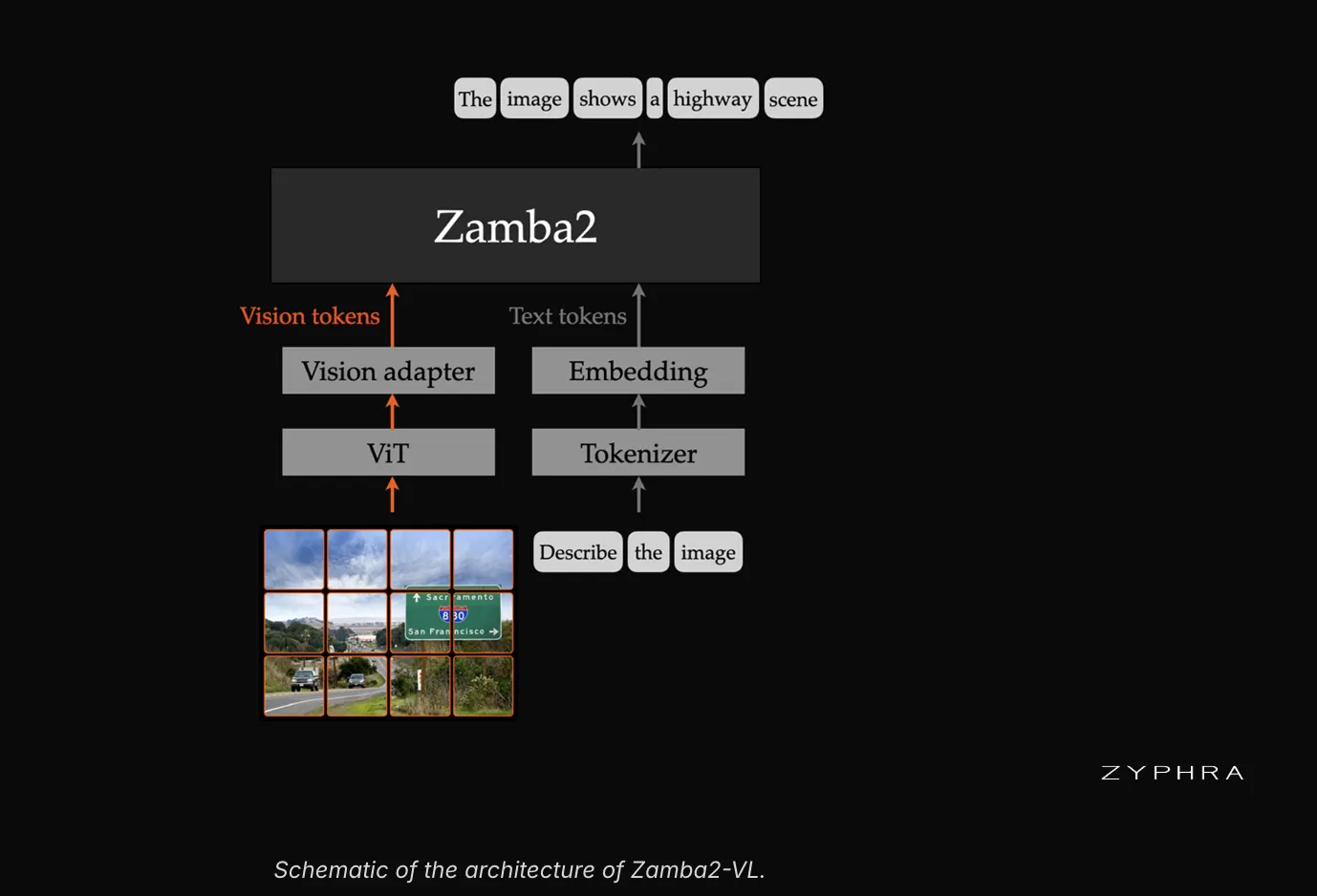

详解小聆AI语音视觉开发板实现语音点播本地TF卡中音乐的开发实现方法
分享AI芯片开发经验
·
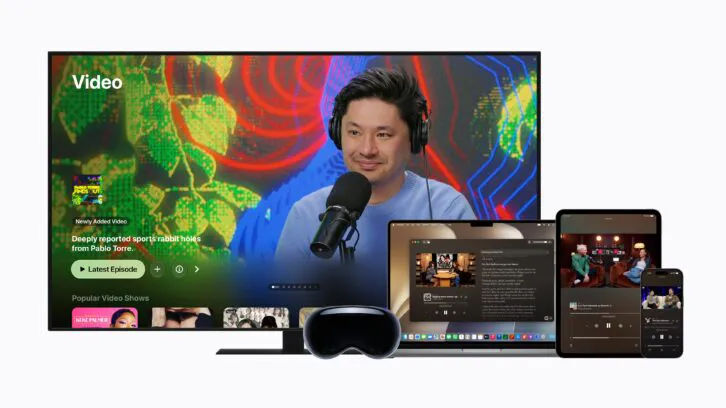
苹果将更新电视上的播客视觉观看体验
实时互动网
·

使用快照捕捉视觉回归,现已进入测试阶段
Sentry Blog
·
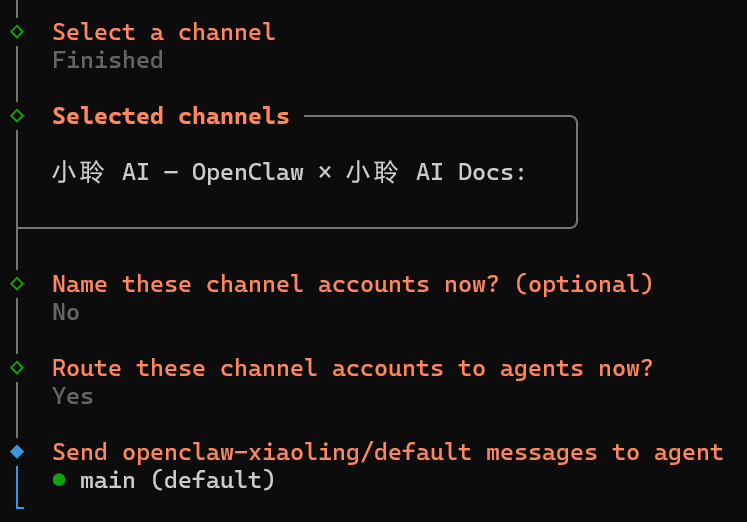
AI语音视觉开发板对接 OpenClaw 龙虾实现多模态交互
分享AI芯片开发经验
·

Neurovia AI展示NeuroStream视觉数据底层基础设施平台
全球TMT-美通国际
·
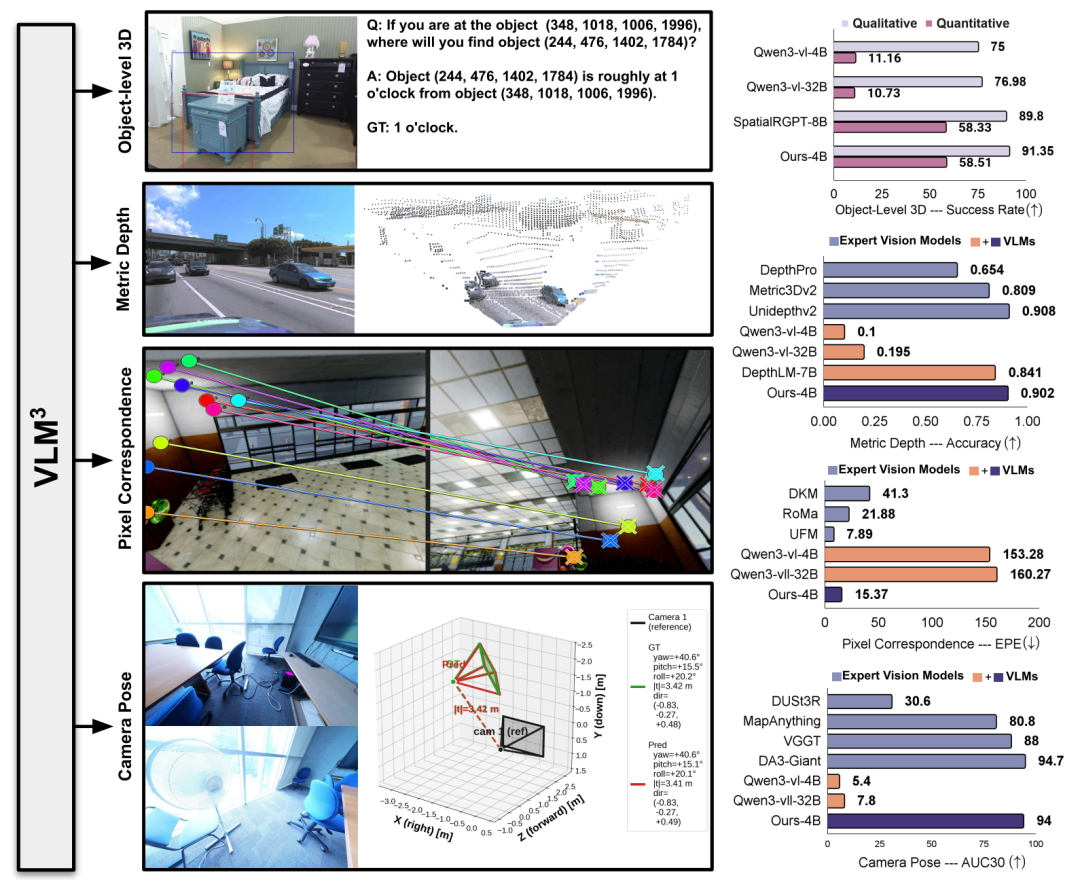

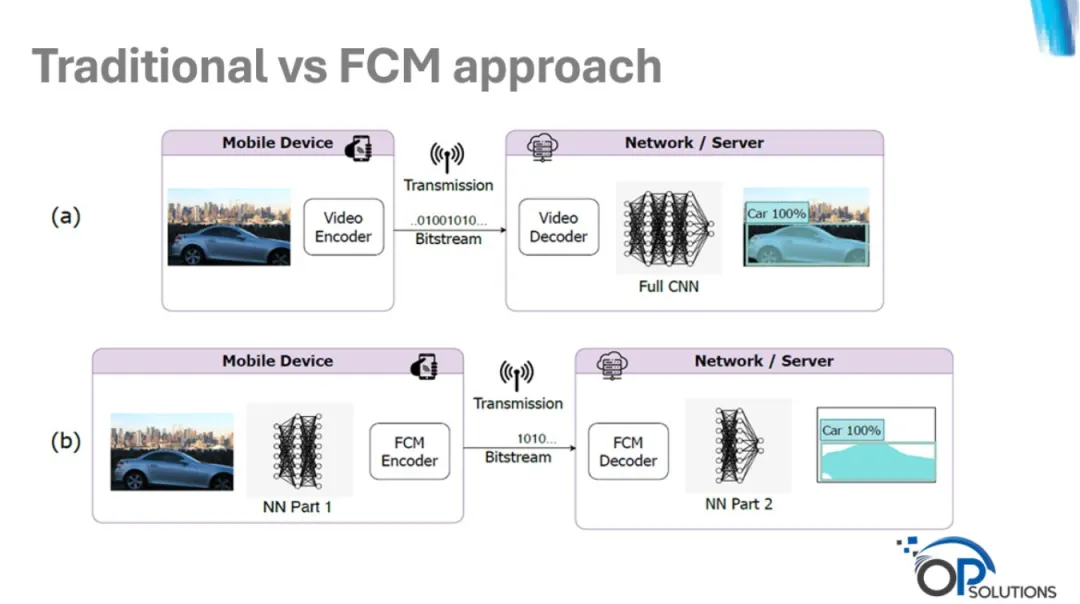
机器视觉压缩的三种途径:VCM、FCM 和 V-Nova 通配符
实时互动网
·