
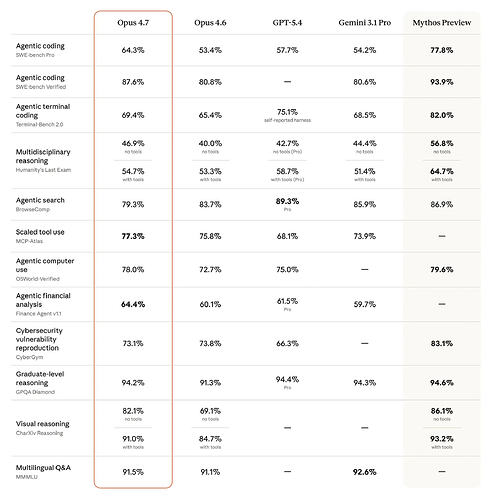
Claude Opus 4.7:优缺点与评测信息汇总
Frytea's Blog
·

利用前沿技术赋能商业创新:基于HarmonyOS 5原子视觉服务的开发实践
DEV Community
·

FPGA与特斯拉定制ASIC在汽车感知中的技术比较
DEV Community
·


类脑神经网络匹配人类视觉和语言处理性能
DEV Community
·

