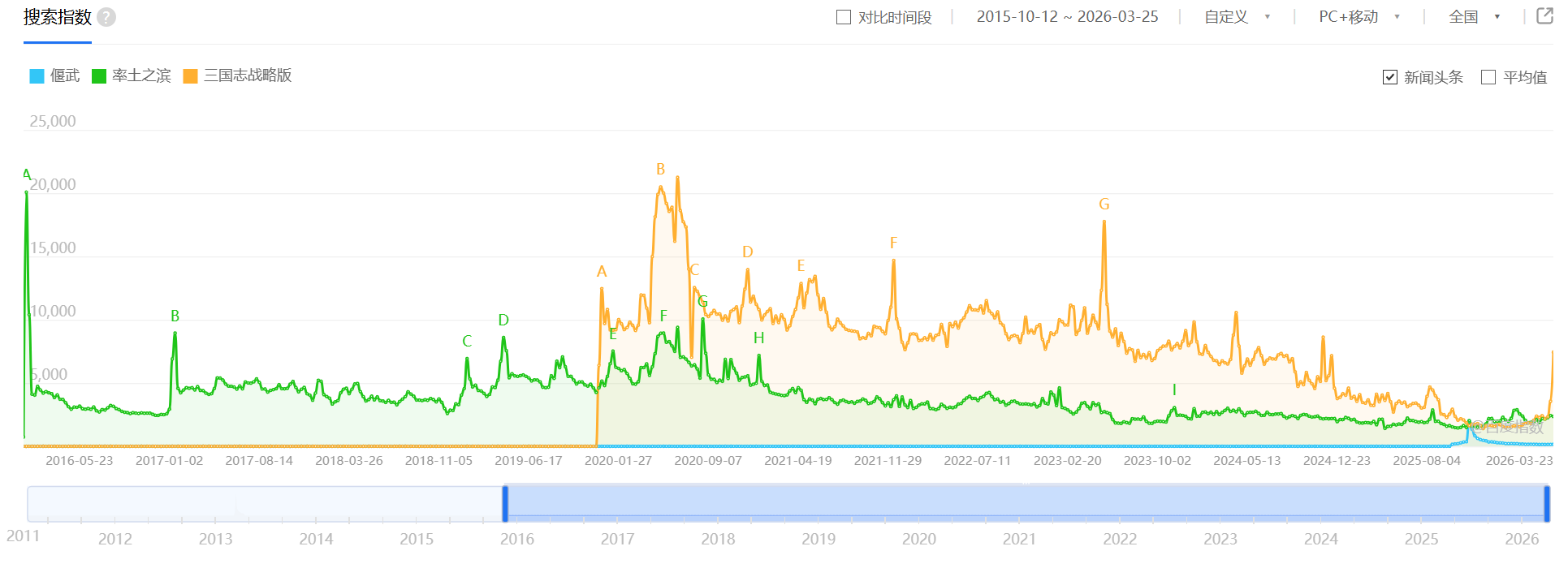
文章讨论了艺术与审美课程,内容涵盖视觉艺术方法论和设计逻辑,包括家具设计、发型设计和穿搭设计,强调实用性与美感。作者认为课程适合初学者,但内容较浅,缺乏深入分析,主要面向对艺术感兴趣的初学者。
本研究提出DFA-CON对比学习框架,旨在有效检测生成式AI工具对视觉艺术创作的版权侵犯与伪造问题。DFA-CON通过建立原创艺术作品与伪造作品之间的亲和力,展现出强大的检测性能,超越了现有预训练模型。
本研究针对当前多模态大语言模型在艺术作品分析中未能有效捕捉细腻解读的问题,提出了一种新颖的框架ArtRAG。该框架通过构建艺术上下文知识图谱,从多角度提供文化和历史背景,使模型能够生成更具语境和文化涵养的艺术描述,并在多个基准测试中超越传统的方法。
IAmMusicFont.com是一个在线字体生成器,专为音乐爱好者和设计师设计,灵感来源于Playboi Carti的专辑封面。用户可以输入文本,实时预览并导出高质量的“I am music font”样式图像,适用于社交媒体和海报等创意项目。未来将增加更多功能和语言支持。
这篇文章介绍了一个节日主题的CSS艺术项目,展示了如何用简洁的代码创造视觉艺术。作者分享了创作过程中的挑战与成就,并计划未来探索CSS动画和过渡效果,以增加动态元素。
生成式人工智能正在革新创作方式,能够自动生成视觉艺术、文本和音乐,节省时间并激发创意。它通过神经网络和算法进行学习,尽管面临伦理和偏见挑战,但未来潜力巨大,能够与人类实时协作,创造个性化作品。
本研究探讨人工智能如何在视觉艺术创作中超越人类认知限制,利用大语言模型通过外星重组方法识别和生成新概念组合,展现AI的创造力潜力。
德克萨斯州的动画工作室以其创新和技术实力著称,融合传统艺术与现代数字技术,创造引人入胜的视觉艺术。这些工作室在品牌传播、教育内容和娱乐制作等领域表现突出,注重与客户合作,确保项目符合客户愿景。德州的动画产业快速发展,未来将继续引领行业潮流。
本文介绍了多种生成音乐的AI模型和方法,如Generative Disco、V2Meow和Video2Music。这些模型通过分析视频和视觉特征生成高保真音频,提升了音乐创作的可解释性和用户交互体验。研究表明,这些技术能够有效生成与视频内容情感相符的音乐,为艺术与音乐的结合提供了新可能性。
本文探讨了艺术风格迁移的研究进展,包括Gatys等人的方法、卷积神经网络在艺术风格分类中的应用、ALADIN架构的细粒度样式相似性表示,以及StyleBabel数据集的构建。同时分析了视觉艺术风格的复杂性与熵的关系,为理解当代艺术风格的演变提供了新视角。
该研究探讨了生成模型在视觉艺术创作中的应用,提出了Intelli-Paint和RAPHAEL等新方法,以提升图像生成的质量与效率。研究强调了扩散技术在艺术创作中的潜力,推动了艺术与技术的融合,拓展了创作表达的可能性。
本文探讨了AI生成艺术,分析了深度神经网络模型的优缺点及其在艺术创作中的应用,特别是现代扩散模型在图像生成中的表现。研究强调了训练数据对艺术创作的影响,并通过案例研究探讨了艺术家与AI模型的互动,以加深对AI艺术创作的理解。
开源AI智能图像技术正在改变视觉艺术,为艺术家提供强大工具。项目如StableCascade和stable-diffusion-webui-forge优化了图像生成和处理速度。Krita的生成式AI插件支持实时绘制和高分辨率处理。Final2x工具实现图像超分辨率,适用于多种操作系统。LoRA-scripts简化了训练过程,提升用户体验。
这篇文章介绍了一种名为「中式旧核」的视觉艺术风格,通过图片和视频展现了千禧年的旧物件。作者感叹这些作品勾起了模糊的回忆,让人感到熟悉又陌生。文章还描述了千禧年之前的时代,市场开放,经济腾飞,生活走向快车道。最后,作者坐上高铁,回望过去,发现已经没有人了。
自上月推出Sora以来,我们与视觉艺术家、设计师、创意总监和电影制作人合作,探讨Sora对创作过程的帮助。
通过创新的统一框架CreativeSynth,实现艺术图像生成的逆向和实时样式转移,精确操纵图像样式和内容,提升保真度和美学精髓,成为定制数字调色板。
Supabase在Launch Week期间推出了一种独特的票务系统,利用Midjourney生成视觉艺术,最终选择了简约的紫色和金色视觉效果。该系统结合了Supabase Edge Function和存储,确保高效分享和实时反馈。用户通过社交媒体分享票据以获得“金票”状态,增加赢取奖品的机会。
完成下面两步后,将自动完成登录并继续当前操作。