

LensVLM:用于文本压缩视觉表示的选择性上下文扩展
Apple Machine Learning Research
·
关于强化学习微调视觉语言模型的鲁棒性与思维连贯性
Apple Machine Learning Research
·
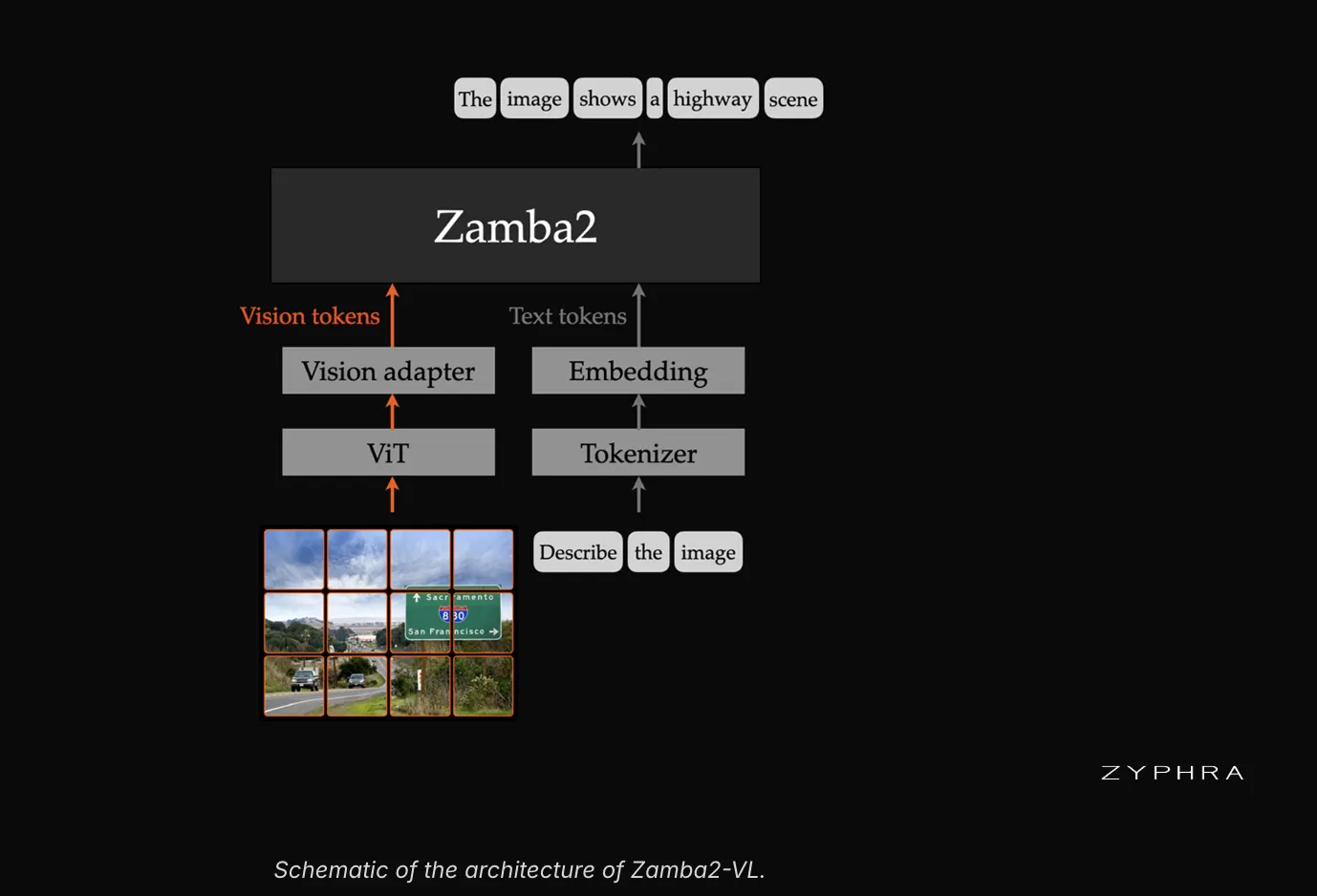
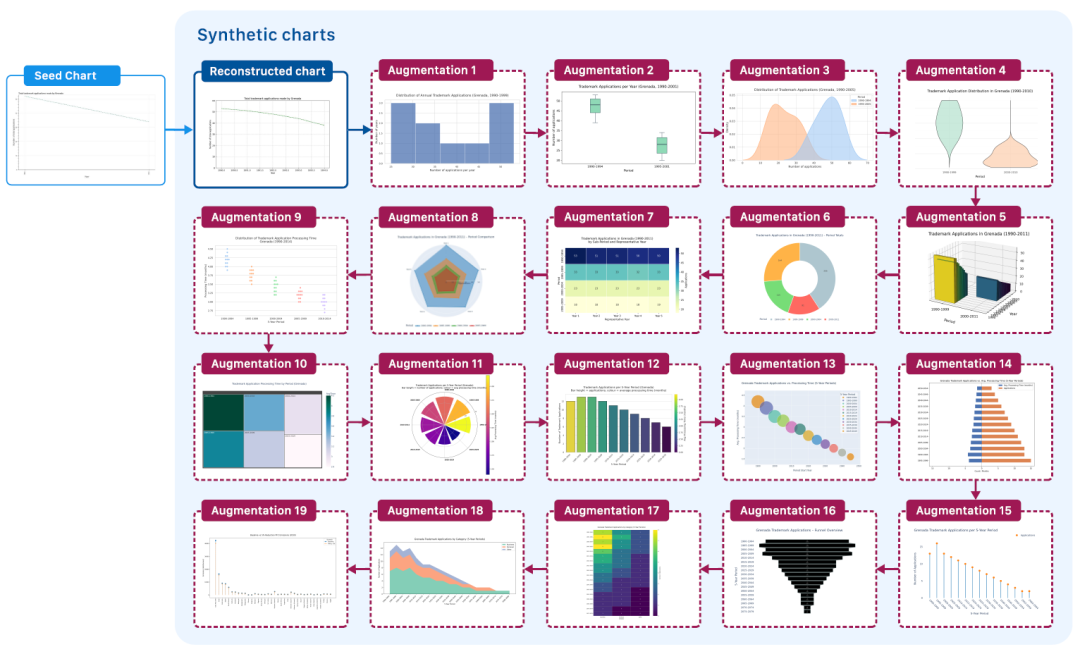
麻省理工/IBM提出迄今为止最大的合成图表数据集ChartNet,生成150万个多样化图表样本
HyperAI超神经
·
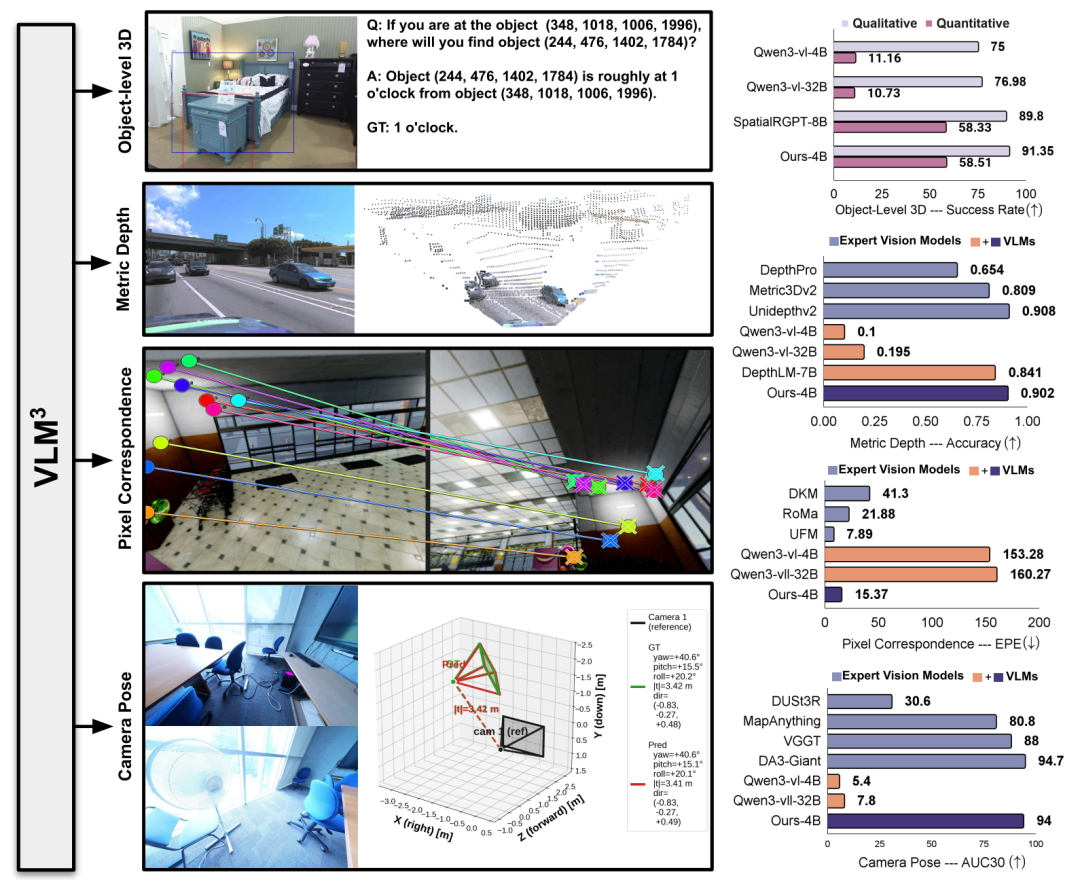
麻省理工学院研究人员教AI模型解读图表
MIT News - Computer Science and Artificial Intelligence Laboratory (CSAIL)
·

大华股份全新发布无人机智能巡检大模型一体机
全球TMT-美通国际
·


解决“打地鼠困境”:一种更智能的去偏见AI视觉模型的方法
MIT News - Artificial intelligence
·
你的logit值知道什么?(答案可能会让你惊讶!)
Apple Machine Learning Research
·
SafetyPairs:通过反事实图像生成隔离安全关键图像特征
Apple Machine Learning Research
·
TrajTok:学习轨迹标记以提升视频理解
Apple Machine Learning Research
·

一种更好的复杂视觉任务规划方法
MIT News - Artificial intelligence
·
