深度学习训练速度主要受内存瓶颈和计算瓶颈的限制,前者是内存访问时间,后者是计算时间。
本研究提出了一种自我推测解码(ASD)方法,旨在解决去噪扩散概率模型(DDPMs)推理中的计算瓶颈,显著提高推理速度。ASD在并行运行时的速度比传统方法快约$ ilde{O}(K^{ rac{1}{3}})$。
清华大学陈键飞团队提出的稀疏注意力机制SpargeAttn,无需训练即可加速多种模型,推理速度提升4-7倍,同时保持端到端精度,有效解决长序列任务的计算瓶颈。
本研究提出了一种名为LightMotion的轻量级相机运动控制视频生成方法,解决了现有方法在微调和推理中的计算瓶颈。通过潜在空间的置换和重采样,LightMotion有效模拟相机运动,提升了生成质量,优于现有技术。
AIxiv专栏促进学术交流,报道超过2000篇研究。吴梓阳等提出的Token Statistics Transformer (ToST)通过线性时间注意力机制提升效率,解决传统Transformer的计算瓶颈,表现优异,具有广泛应用潜力。
该论文评估了高性能网络推断的近似方法,探讨其在自定义硬件中的有效性。提出了剪枝方法、NEON编译器优化和数字乘法器等多种算法和优化方案,以提高性能和能效,解决计算瓶颈和能量消耗问题。
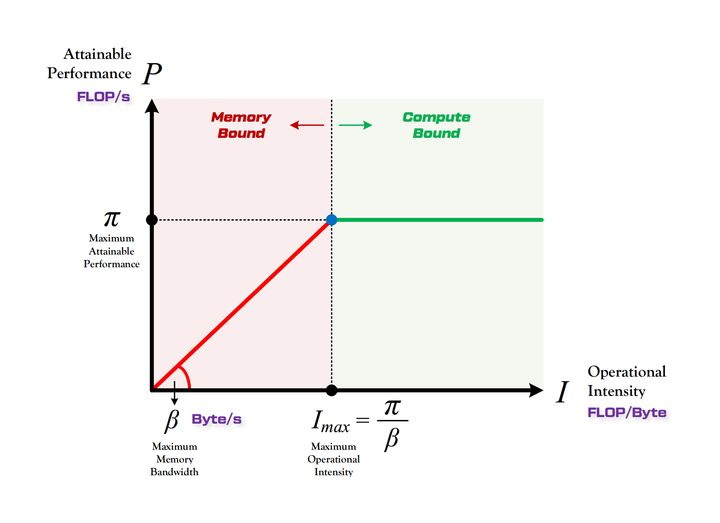
Roofline模型通过运算强度与带宽分析计算性能。运算强度是运算量与访存量的比值。图中红色区域表示带宽瓶颈,绿色区域表示计算瓶颈。优化策略包括提高算力和带宽,需根据不同瓶颈选择合适的优化方法。
该论文介绍了一种名为DDSM的新型框架,通过使用自适应调整的神经网络解决了生成过程中的计算瓶颈问题,提高了扩散模型的效率,并且可以与其他扩散模型集成,不影响生成质量。
完成下面两步后,将自动完成登录并继续当前操作。