张量并行是一种模型并行技术,通过在特定维度上分割张量,将计算分配到多个设备,适用于参数量巨大的模型。本文介绍了在PyTorch中实现张量并行的设计和训练步骤。
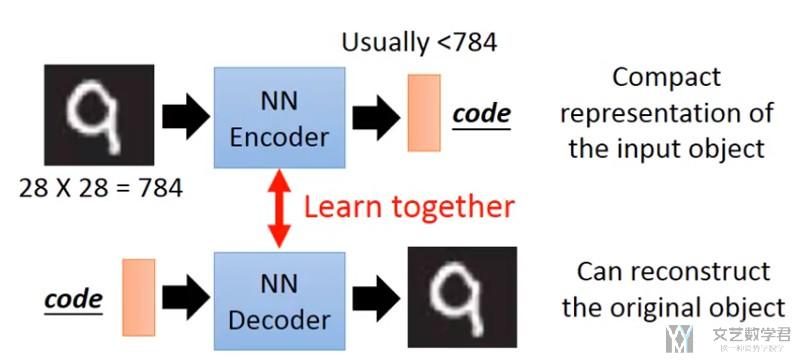
本文介绍了自编码器的基本原理及其在Pytorch中的实现,主要用于动漫头像重构。自编码器通过编码器将输入图像压缩为向量,再通过解码器进行还原。文章详细阐述了网络结构、训练步骤及结果展示。
DeepSeek的R1模型利用无须人类反馈的群体相对策略优化(GRPO)技术,提升了大语言模型的推理能力。GRPO使模型能够通过比较多个答案的得分进行自主学习。使用Unsloth,普通GPU也能训练15B参数的模型。文章详细介绍了训练步骤,包括环境设置、模型初始化、数据集准备和奖励函数设计,从而实现更高效的推理模型。
本文介绍了如何使用HuggingFace Transformers微调大型语言模型(LLMs)。微调是在特定任务或数据集上训练预训练模型,以提升其在特定领域的表现。文章讨论了微调的重要性、应对模型生成不准确内容的策略(如检索增强生成、提示工程和微调),以及微调的具体步骤,包括选择模型、准备数据、设置参数、创建训练器、训练和评估。
本文介绍了Stable Diffusion中的Lora模型,它是一种用于微调大语言模型的低次序适应技术。Lora模型允许用户在不修改SD大模型的情况下,利用少量数据训练出具有特定画风、IP或人物特征的模型。文章还介绍了Lora模型的使用方法和训练步骤。
本文总结了大模型的技术、本质和未来趋势,介绍了人工智能的发展历史和大模型的训练步骤。同时讨论了大模型面临的问题和相关技术,如Prompt Engineering、RAG、LLM Agent和多模态学习。最后展望了未来AI与人类的协同关系的发展趋势。
完成下面两步后,将自动完成登录并继续当前操作。