

一分钟读论文:《自动化AI研发中的隐蔽破坏与监控评估》
Micropaper
·

人工智能时代的评估指标
OpenAI
·

大型语言模型函数调用的不确定性量化
Apple Machine Learning Research
·

LLM评估框架比较:如何实际衡量您的模型表现
MachineLearningMastery.com
·
主动代理研究环境:模拟活跃用户以评估主动助手
Apple Machine Learning Research
·
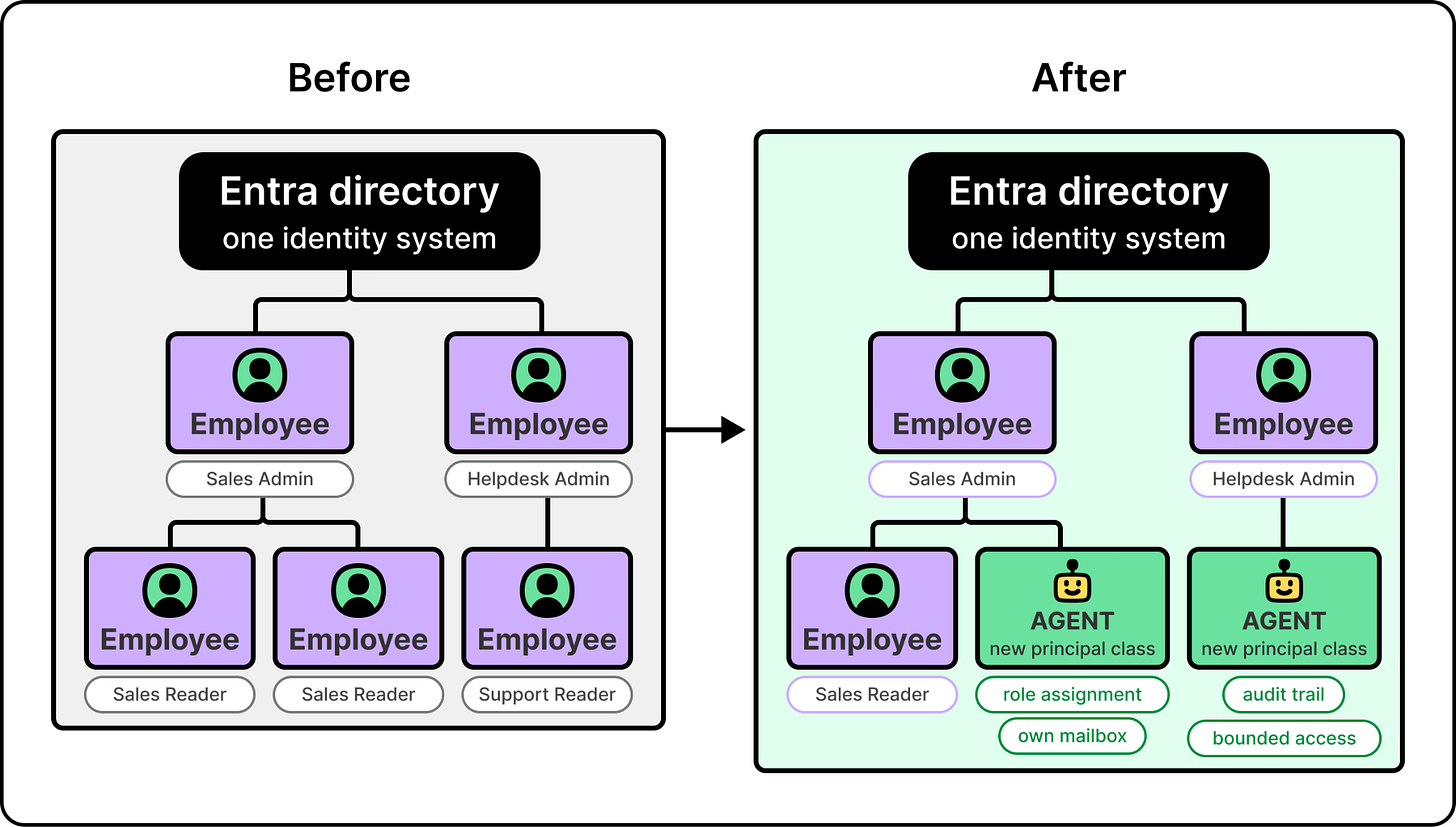
微软如何在企业规模上部署AI代理
ByteByteGo Newsletter
·
在编码评估中区分信号与噪声
OpenAI
·

Flags SDK 现在以 10 倍的速度评估标志
Vercel News
·

一分钟读论文:《AgentGym2——从理想化基准到真实世界部署的评估范式转移》
Micropaper
·


哪个互联网通信云适合中小企业
实时互动网
·
DigitalOcean 评估:推理堆栈的生产模型和路由测试
The DigitalOcean Blog
·

读取代理追踪是你无法通过评估进行调用的方式
Sentry Blog
·
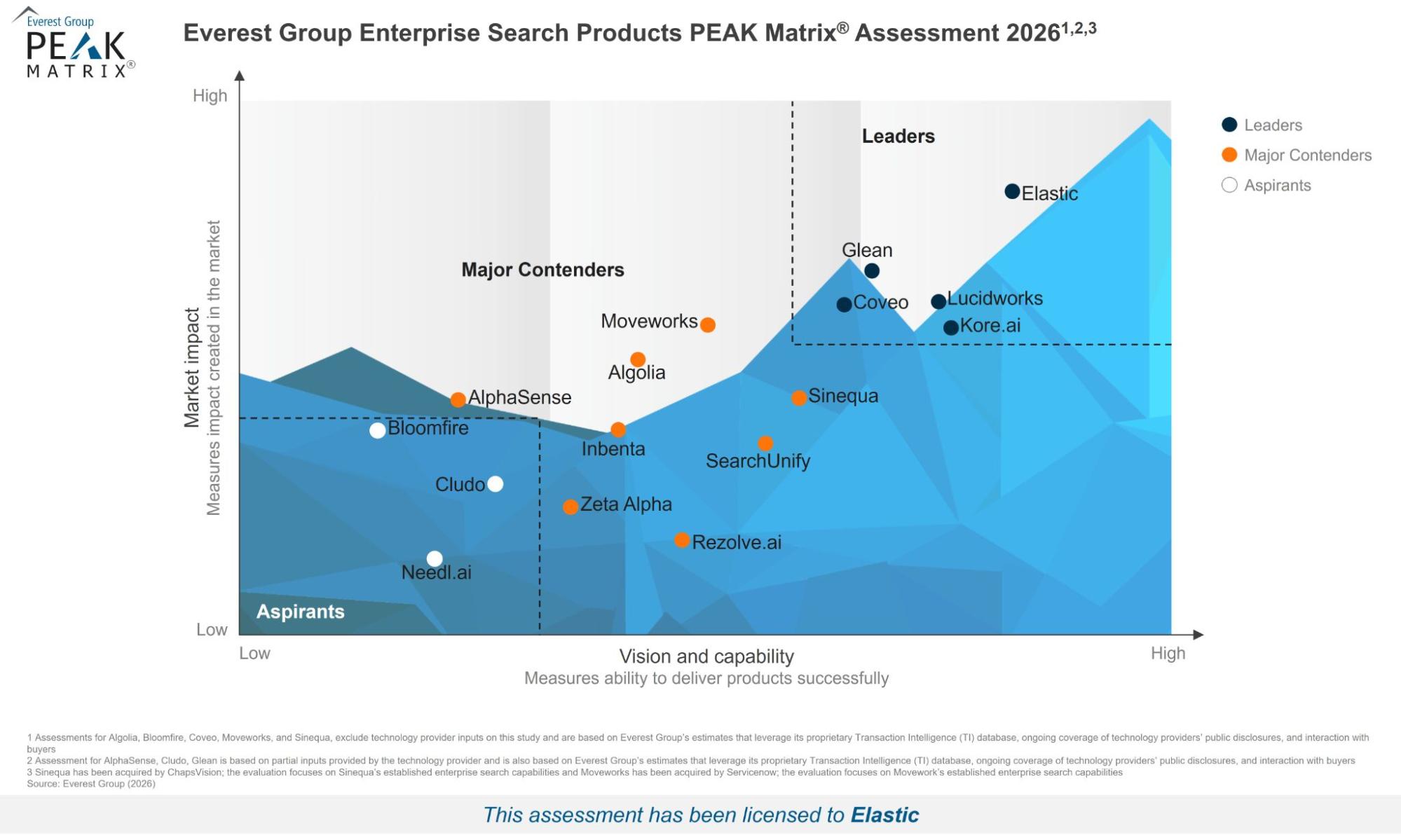
Elastic在2026年Everest Group企业搜索产品PEAK Matrix®评估中被评为领导者
Elastic Blog - Elasticsearch, Kibana, and ELK Stack
·
