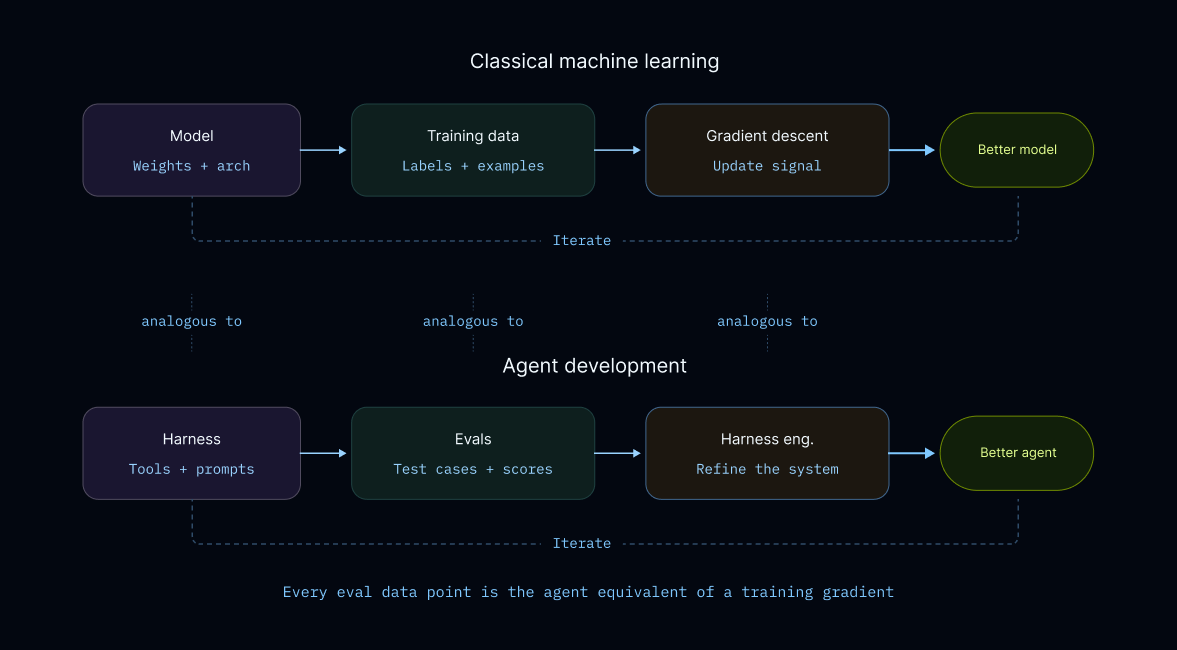
通过使用评估数据(evals),我们可以迭代改进智能代理的性能。评估数据作为训练数据,指导代理学习和优化行为。强调数据质量和设计的重要性,以避免过拟合,并通过手动编写、生产追踪和外部数据集获取评估,确保代理在新输入上的泛化能力。
本研究探讨了大型语言模型(LLMs)在评估中面临的数据污染问题,特别是训练与评估数据重叠的影响。通过审查47篇论文,发现现有检测方法在某些假设下表现接近随机,强调了明确假设和验证有效性的重要性。
本文介绍了提升模型能力的简单有效方法,包括搞出好的训练数据、评估数据质量和训练好的模型。这个方法适用于各种场景,但可能会遇到一些难题。通过找帮手可以克服这些困难。
完成下面两步后,将自动完成登录并继续当前操作。