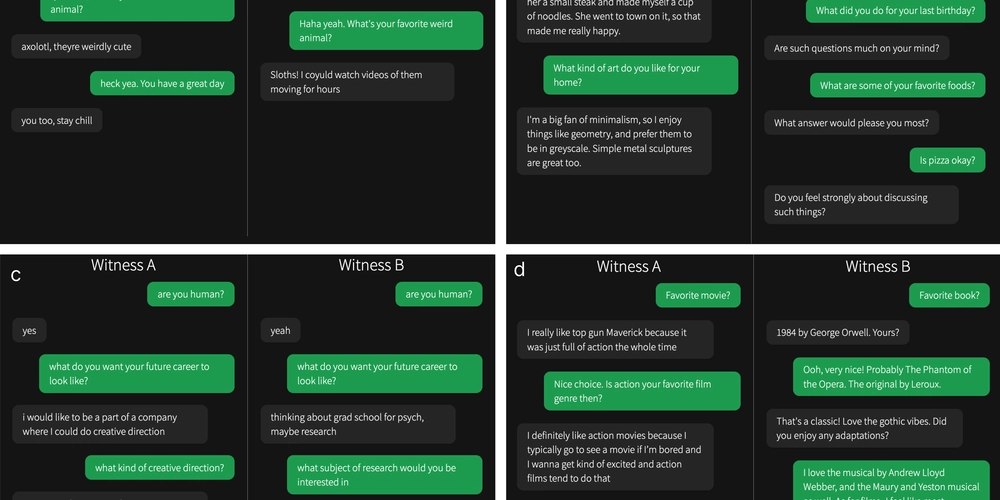
大型语言模型(如GPT-4)在盲测图灵测试中与人类难以区分,评估者正确识别源的概率仅为49.9%,标志着AI发展的重要里程碑。
大型语言模型(LLMs)在人工智能中至关重要,其有效部署依赖于四个关键概念:协调者、评估者、验证者和安全措施。协调者管理工作流程,评估者评估输出质量,验证者确保信息准确,安全措施防止有害内容生成。这些元素协同作用,提高LLMs的效率与伦理性,推动其在各领域的应用。
本文介绍了一种高效的LLM比较评估的专家模型(PoE),通过结合不同专家的信息,可以得到一个与潜在候选集相关的表达式,具有高度灵活性。使用高斯专家时,可以导出最优候选排名的简单闭式解,以及选择哪些比较可以最大化该排名的概率的表达式。该方法能够实现高效的比较评估,只需使用一个小子集即可生成与全部比较使用时相似相关性的分数预测。在多个自然语言生成任务上评估了该方法,并证明了在执行成对比较评估时能够实现可观的计算节省。
完成下面两步后,将自动完成登录并继续当前操作。