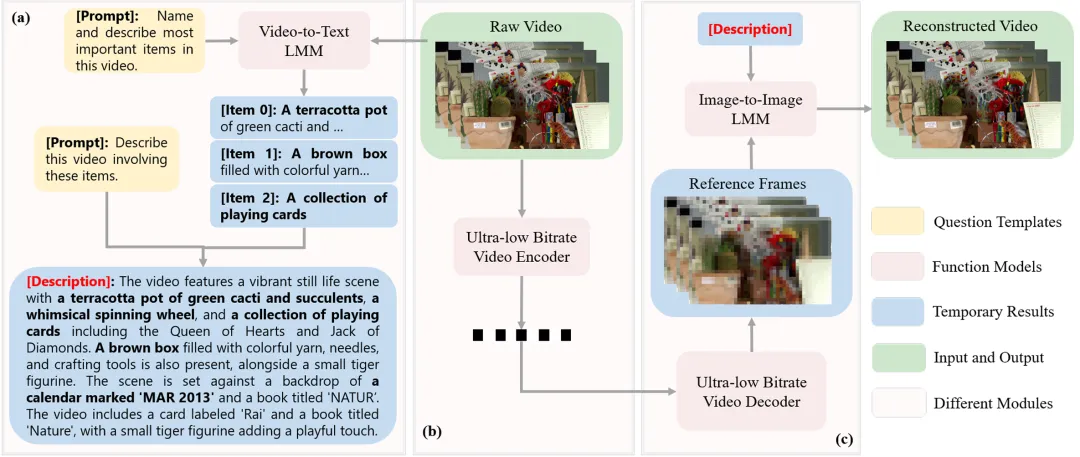

具识智能全球首发具身语义智能体系统insightOS Semantic
全球TMT-美通国际
·
🔍 别让大模型"想太多":SKILL开发中的语义陷阱与抗幻觉设计
像清水一般清澈透明
·

苹果音乐的多语言语义检索
Apple Machine Learning Research
·



用 LLM + 语义聚类,把海量用户评论提炼成四级 VOC 标签体系
亚马逊AWS官方博客
·


语义过载:为什么人工智能代理会错误地获取事实
Redis Blog
·

基于分支的语义代码搜索与Qdrant
Qdrant - Vector Database
·