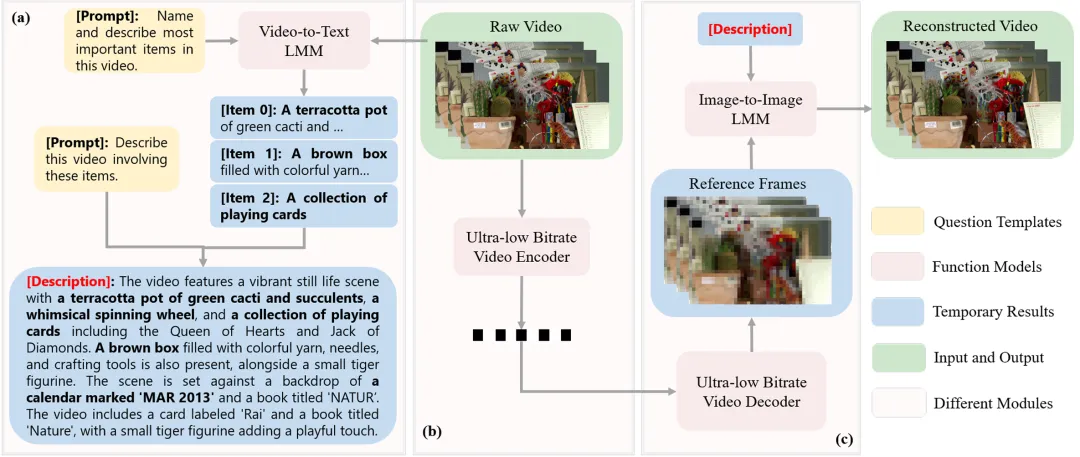
近年来,超低码率视频压缩面临性能挑战,导致视频质量下降。为此,提出了一种基于多模态大模型的语义压缩方法LMM-VSC,通过提取语义信息和生成参考视频,显著提高了超低码率下的视频质量。实验表明,该方法在保持感知质量的同时,降低了68.4%的比特率,具有较高的实际应用价值。
本文介绍了一种基于图形表现的异构人脸识别方法(G-HFR),该方法利用马尔可夫网络表示异构图像补丁,考虑空间兼容性,实验结果表明其性能优于现有方法。此外,提出了一种新的元宇宙通信范式,通过三维面部描述符实现语义压缩,提升了灵活性和效率,促进了基于人工智能的理解。
本研究提出了一种新颖的语义压缩方法,旨在提高基于Transformer的大型语言模型(LLM)在长上下文处理中的效率。通过量化KV缓存激活和上下文压缩,LLM能够处理更长文本而无需显著计算开销。实验表明,该方法有效扩展了上下文窗口,并显著降低了长文档问答的成本,展示了LLM在长上下文理解方面的潜力与挑战。
本文介绍了UniMem框架,提出了UniMix算法,显著降低计算复杂度并提升对话任务性能。同时,介绍了LongMem框架和语义压缩方法,扩展了大型语言模型的上下文窗口,改善文本生成效果。LLoCO方法通过上下文压缩和高效微调,提高了长文档问答的效率,提供了有效的长上下文处理方案。
本文介绍了多种扩展大型语言模型(LLMs)上下文窗口的方法,包括RoPE扩展、E2-LLM、语义压缩和递归上下文压缩等。这些方法有效提升了模型处理长文本的能力,降低了计算成本,并在多个任务中表现出优越性能。此外,研究还发布了新的长上下文模型和基准测试,以支持未来研究。
本文提出了一种新颖的语义压缩方法,旨在提升大型语言模型(LLM)处理长文本的能力。该方法通过减少语义冗余,将上下文窗口扩展至128k个令牌,同时显著降低计算开销和内存使用。实验结果显示,该方法在问答和摘要任务中表现优异,为高效处理长文本提供了解决方案。
本文提出了一种新颖的语义压缩方法,使大型语言模型(LLM)能够处理更长文本而无需显著的计算开销。该方法通过减少语义冗余,扩展了LLM在问答和摘要等任务中的上下文窗口。同时,研究介绍了LongMem和UniMem框架,提升了模型对历史上下文的利用能力,并提出了Attention Transition技术,显著改善了长文本理解。
本文提出了一种新颖的语义压缩方法,使大型语言模型(LLM)能够在处理长文本时减少计算开销。该方法通过降低语义冗余,提升了模型在问答和摘要等任务中的表现,并展示了在保持语义完整性的同时实现高达20倍的压缩效果。
完成下面两步后,将自动完成登录并继续当前操作。