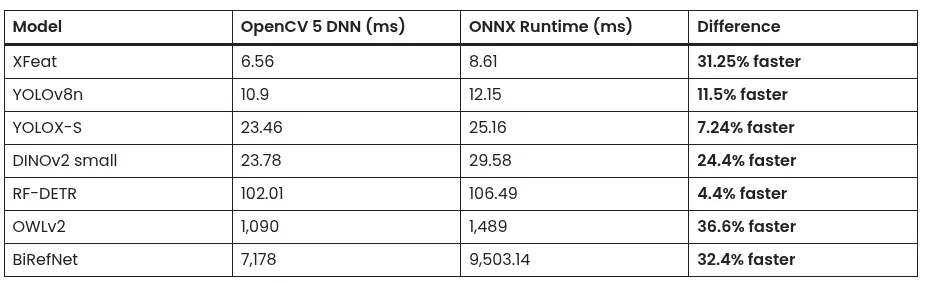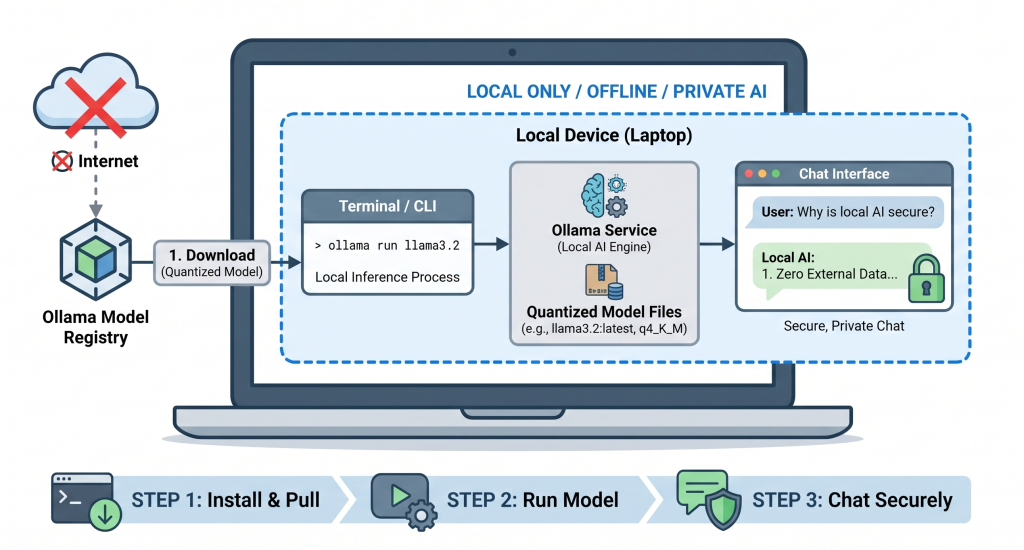
在15分钟内使用Ollama运行本地AI模型
MachineLearningMastery.com
·


AI论文评审:自一致性提升语言模型中的链式思维推理
freeCodeCamp.org
·


连续扩散口语语言模型的缩放特性
Apple Machine Learning Research
·
残余上下文扩散语言模型
Apple Machine Learning Research
·
学习扩散语言模型的解码策略
Apple Machine Learning Research
·
关于强化学习微调视觉语言模型的鲁棒性与思维连贯性
Apple Machine Learning Research
·

为什么意图预测需要超越传统语言模型(LLM)
Stack Overflow Blog
·
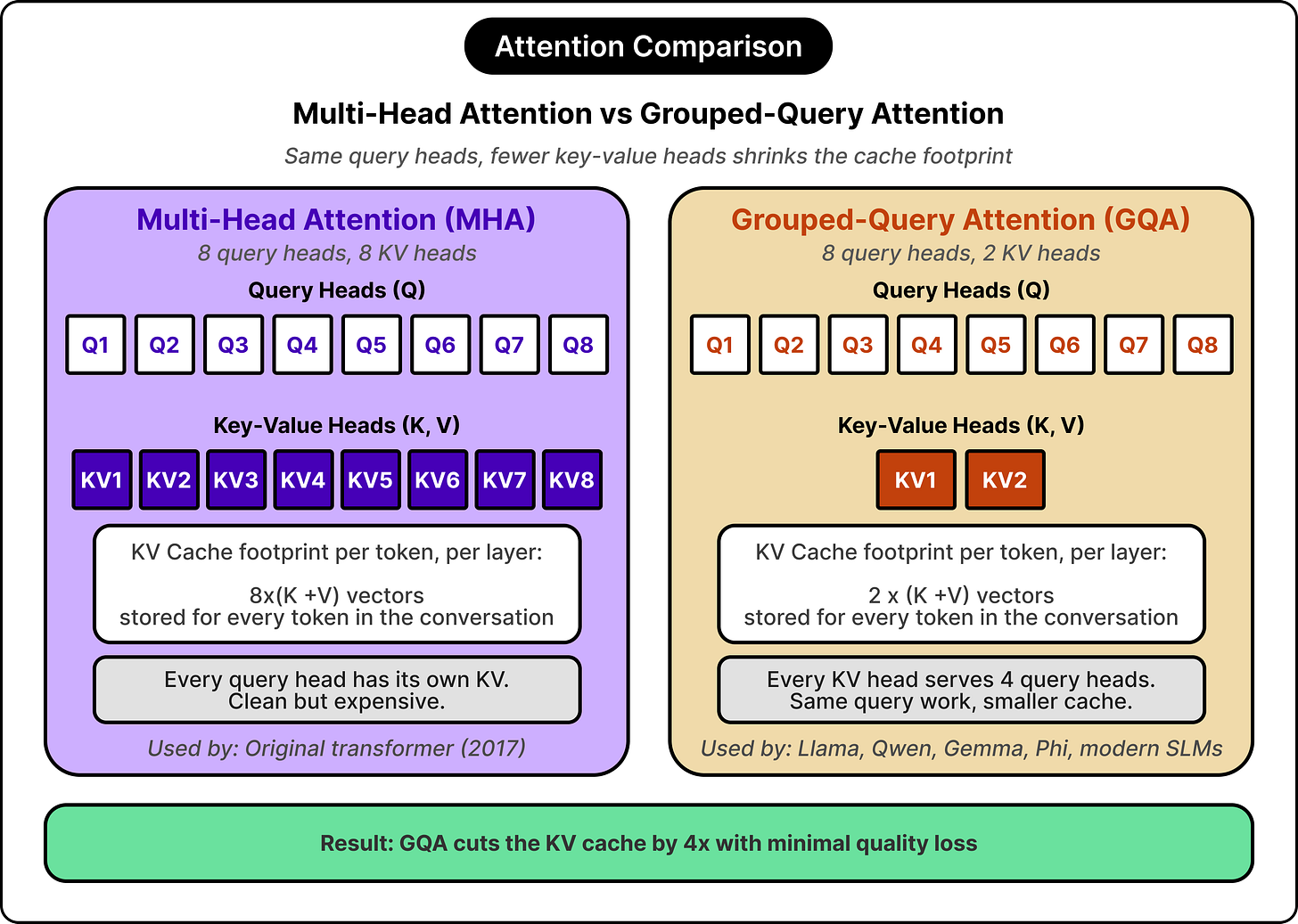
大型语言模型与小型语言模型
ByteByteGo Newsletter
·
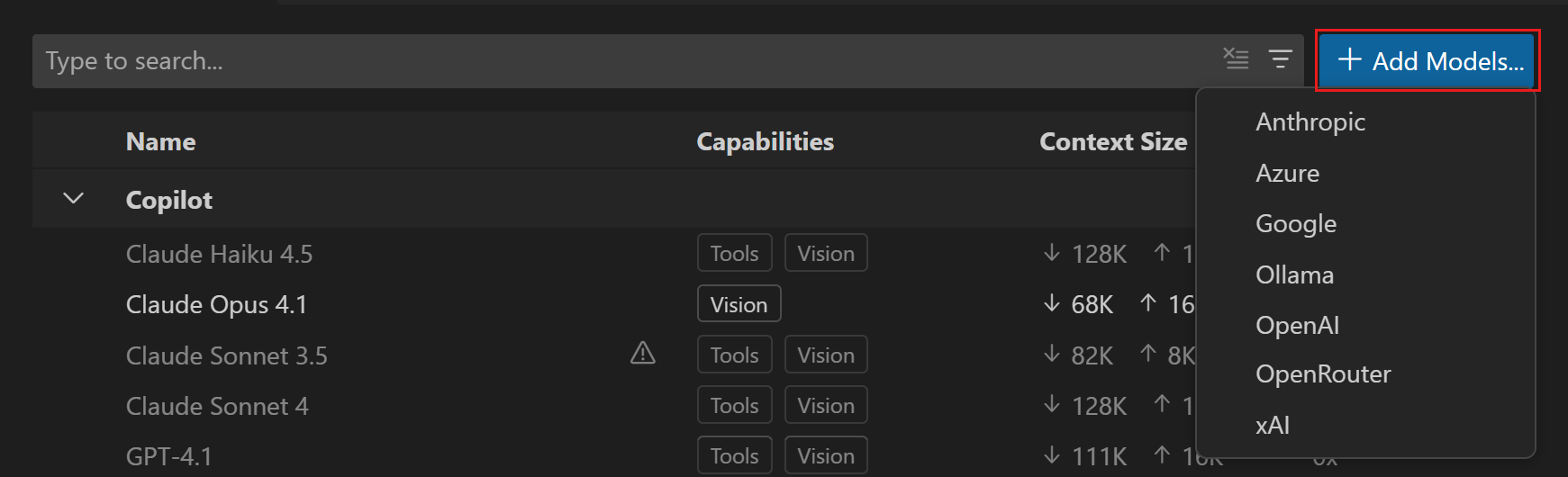
在VS Code中使用自带语言模型密钥
Visual Studio Code - Code Editing. Redefined.
·
AI 博客问题挑战
失眠海峡
·

什么是AI语音开发?从技术链路到落地场景的完整拆解
实时互动网
·