本研究提出一种新方法,通过识别冗余字面和负例,显著减少归纳逻辑编程中的无意义规则问题,假设空间缩减,学习时间减少99%,预测准确性保持不变。
本文介绍了一种新方法“Rumi框架”,通过让生成对抗网络(GANs)学习避免负样本,提升目标数据分布的表示能力。实验证明,该方法在多个数据集上优于标准GAN和LSGAN,并有效解决不平衡数据集中的类别不平衡问题。
本研究使用基于阈值的弱监督模型和梯度可解释人工智能技术,在中风幸存者的数据集中探索时序数据的可行性。通过前馈神经网络模型和梯度,识别涉及补偿动作的显著框架。评估结果显示,该方法在召回率和F2分数上取得了较高的成绩。这表明基于梯度的可解释人工智能技术在时序数据中具有潜力,可减少模型训练中的标签工作量。
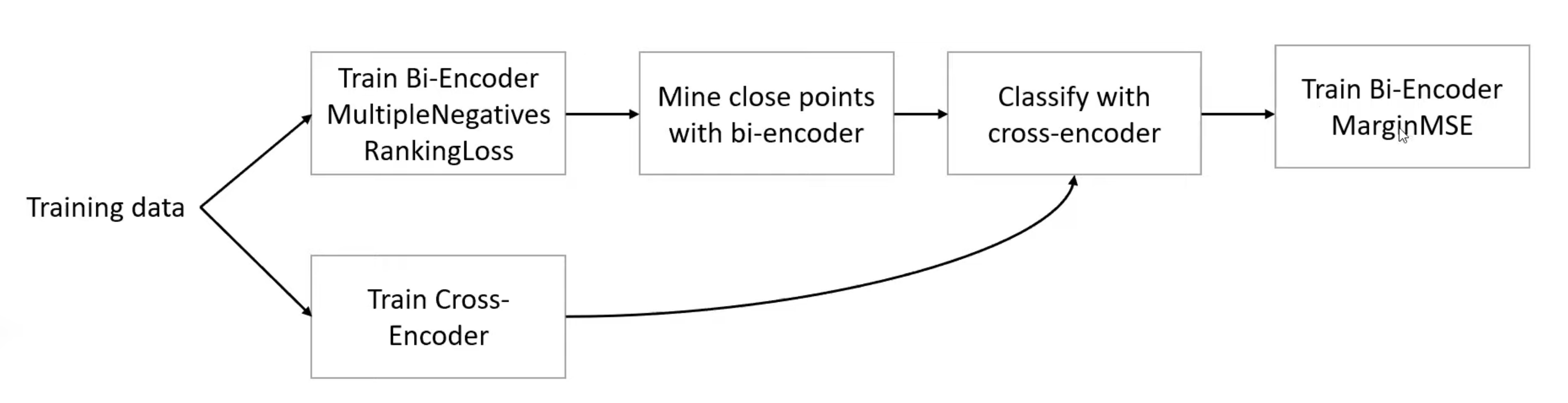
寻找负例的技巧很重要,可以通过数据集结构或BM25算法来实现。例如,在问答数据集中,可以将低赞答案作为负例;使用BM25找到与目标文本相似的文本,并随机选择一个作为负例,这在项目中效果良好。
完成下面两步后,将自动完成登录并继续当前操作。