
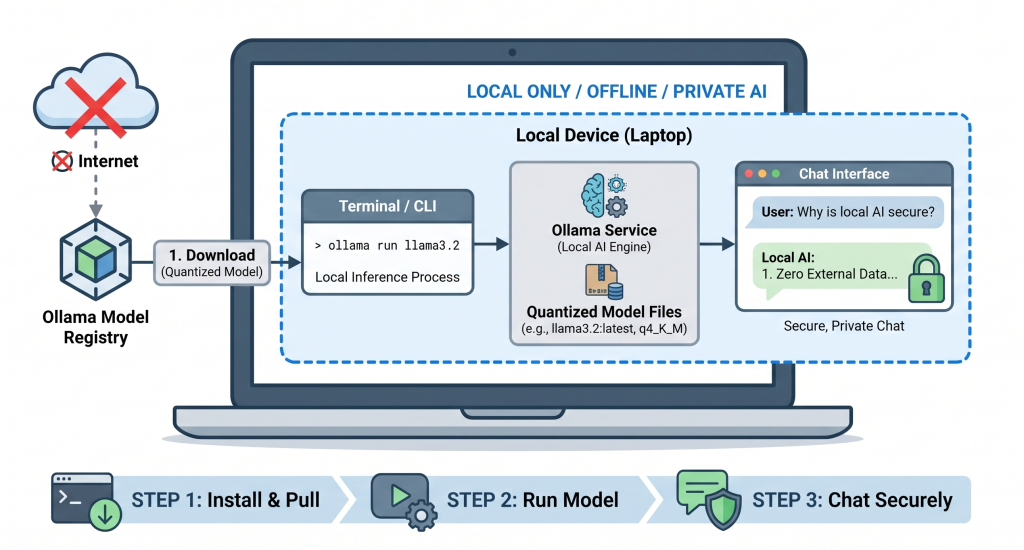
在15分钟内使用Ollama运行本地AI模型
MachineLearningMastery.com
·

人工智能革命不会被电视播出——而是将被量化
The New Stack
·

HNSW与LSH:Elasticsearch如何在每秒15,000个查询下实现0.99的召回率@10——以及其成本
Elastic Blog - Elasticsearch, Kibana, and ELK Stack
·



低位推理如何实现高效的人工智能
Dropbox Tech Blog
·

逐步量化大型语言模型:将FP16模型转换为GGUF
MachineLearningMastery.com
·

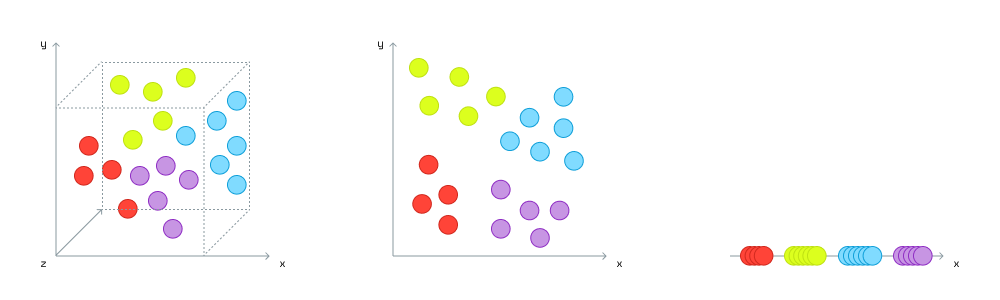
Redis查询引擎现已支持量化和降维技术
Redis Blog
·

微软原生1位大型语言模型有望为日常CPU带来高效的生成式人工智能
InfoQ
·

在Word中使用强大的Gemma 3 QAT模型(100%私密)
DEV Community
·

在 AWS Graviton 上运行大语言模型:CPU 推理性能实测与调优指南
亚马逊AWS官方博客
·


