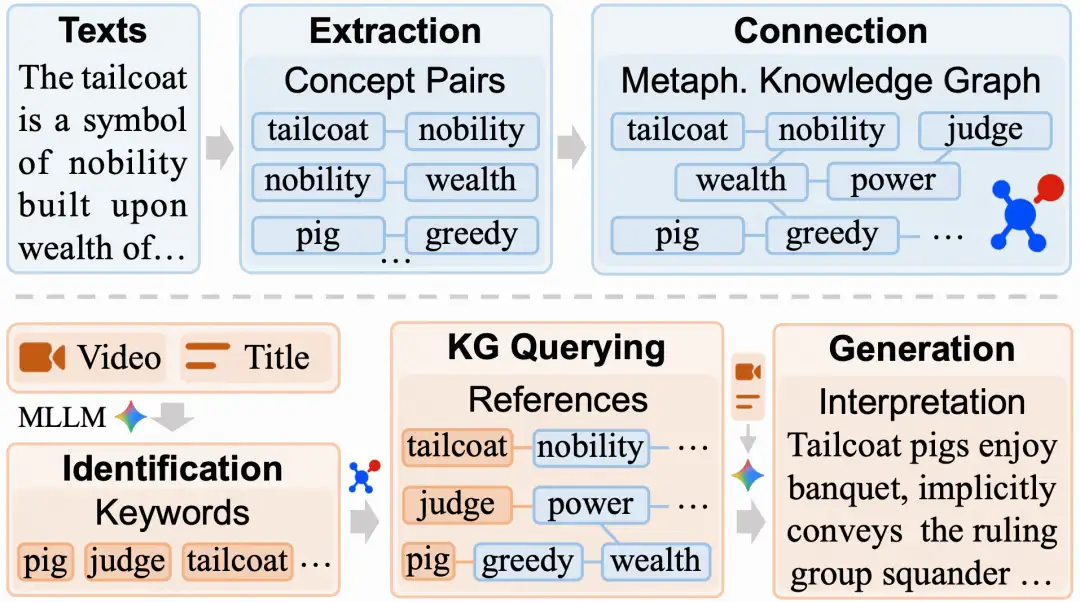
在短视频和社交媒体时代,创作者通过隐喻表达深层意涵。快手与科研机构合作,提出隐喻视频理解基准MetaphorVU,以提升多模态大模型的隐喻理解能力。研究发现现有模型在跨域映射上存在不足,导致理解失败。为此,团队开发了MetaphorBoost,通过隐喻知识图谱增强模型理解能力,取得显著提升。这项研究为多模态理解提供了新的评测标准和增强路径。
本研究针对中文自然语言处理中的隐喻理解挑战,开发了中文多模态隐喻广告数据集(CM3D)和隐喻映射识别模型(CPMMIM)。该模型通过模拟人类认知过程,提高了隐喻识别的准确性,实验结果验证了其有效性,推动了隐喻理解的研究进展。
为了评估大型语言模型(LLMs)对隐喻理解的能力,研究人员发布了隐喻理解挑战数据集(MUNCH),其中包含超过10k个含隐喻用法的句子的释义和1.5k个含不恰当释义的实例。实验表明,MUNCH对LLMs来说是一个具有挑战性的任务。
完成下面两步后,将自动完成登录并继续当前操作。