Flock Safety的AI监控系统在美国迅速扩张,尽管声称提高公共安全,但存在侵犯隐私和滥用权力的风险。执法部门可在无令情况下访问数据,可能导致种族偏见和法律灰区。专家呼吁以社区建设替代泛化监控,强调真正的公共安全应来自社区投资,而非无处不在的监控。
AI短剧《桃花簪》因未经允许使用汉服爱好者照片引发肖像权争议,网友担忧“AI偷脸”现象。明星如肖战、杨紫也面临类似问题,普通人同样受到隐私侵犯。法律监管正在加强,专家建议公众保护个人肖像,及时维权。
记者朱莉亚·安温因发现Grammarly的“专家审查”AI功能未经许可使用她的身份,提起集体诉讼,指控该公司侵犯隐私和商业权益。Grammarly已暂停该功能,并承认未妥善处理用户反馈。
从2025年7月起,Urban VPN等浏览器扩展将默认收集800万用户的AI对话数据并出售,严重侵犯隐私。作者呼吁公众警惕技术滥用,强调应重新掌控技术发展方向。
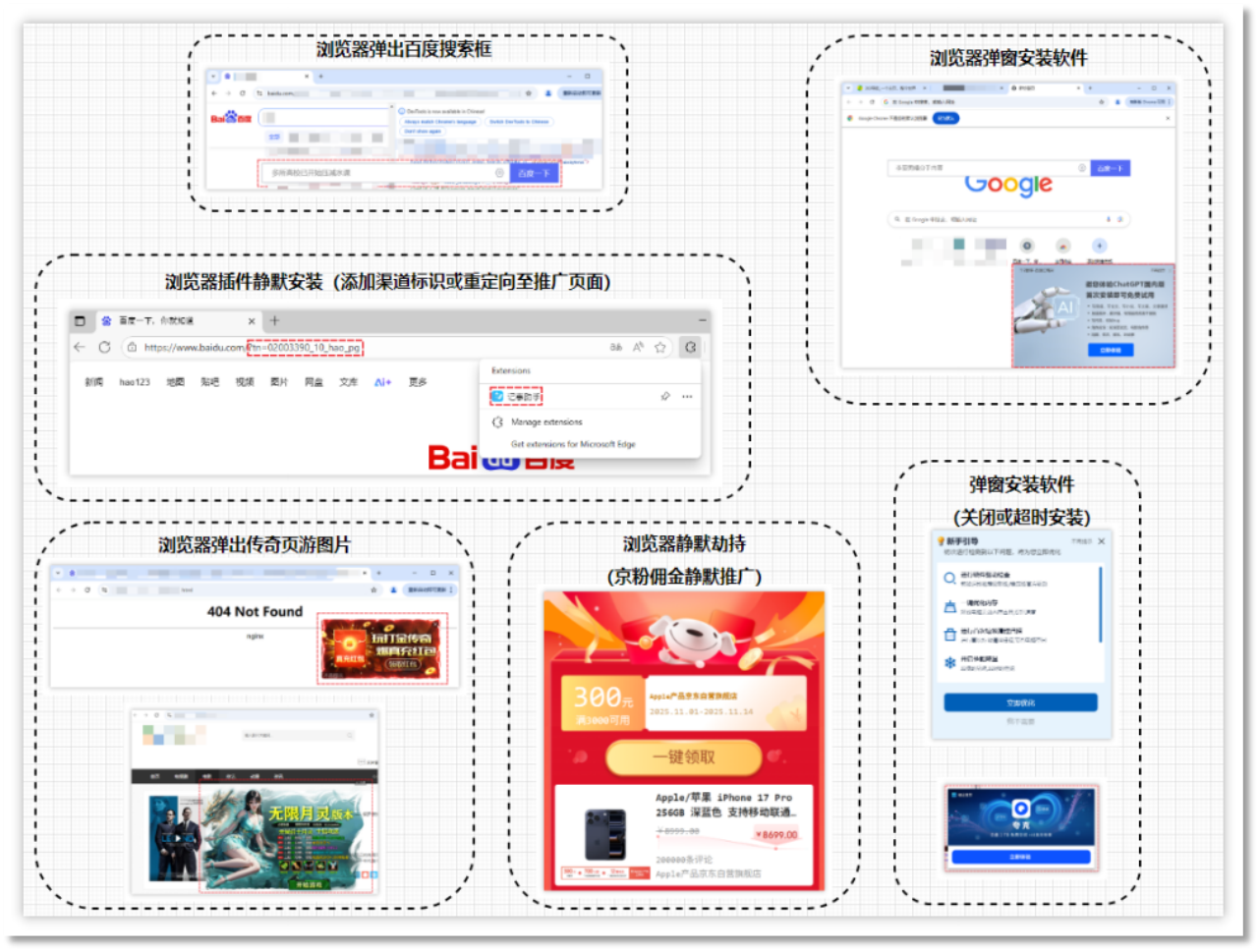
火绒安全报告指出,360旗下的鲁大师利用云控技术进行流量劫持,未经用户同意读取浏览器历史,严重侵犯隐私。鲁大师根据用户访问记录调整弹窗频率,其推广行为类似恶意软件,已成为行业常态。
Astral公司推出PYX,一个Python原生包注册表,提升生态系统的速度和安全性。Google发布Gemma 3 270M模型,适用于设备端应用。伊利诺伊州禁止未经审查的AI聊天机器人用于心理治疗,以保护脆弱人群。Meta因未经同意访问Flo应用的女性健康数据被裁定侵犯隐私。
自春节以来,AI大模型迅速改变各行业,但安全风险增加,数据泄露和隐私侵犯问题突出。企业需建立全生命周期的安全防线。火山引擎在“AI时代,安全领航”大会上指出,安全是释放大模型价值的关键,并针对六大安全挑战提出解决方案,如大模型应用防火墙和机密计算平台,以确保数据安全与性能平衡。
谷歌将向德克萨斯州支付13.75亿美元,以解决因隐私侵犯而提起的诉讼。德州检察长指控谷歌非法追踪和收集用户的地理位置、隐私搜索和生物识别数据。
文章讨论了七种有争议的人工智能工具,如DeepNude、DeepFakes和AI钓鱼工具,指出它们可能引发的法律和伦理问题,包括隐私侵犯、虚假信息传播和网络犯罪。作者强调负责任使用AI的重要性,呼吁谨慎和道德地使用这些技术。
在数字时代,数据泄露和隐私侵犯频繁,强大的网络隐私解决方案至关重要。传统身份管理系统面临数据集中化风险,难以保护用户隐私。Rust语言因其性能和安全性,成为开发安全网络应用的理想选择,提供丰富的加密库,支持安全数据处理,确保内存安全和并发性,适合构建高性能网络服务。
AI监工在职场引发争议,监控员工的打字速度和鼠标活动,甚至发出警告。虽然有助于工作自动化,但侵犯隐私,增加心理压力,导致员工与企业关系紧张。
利用大型语言模型将其嵌入虚拟化身或以其作为叙述形式,通过用户配置文件进行提示工程和微调,促进XR的包容性体验,增强XR环境的互动性。需要研究隐私侵犯问题和用户的隐私关注和偏好。
本文提出了一种基于实体级别的方法来量化语言模型的记忆能力,并提供了一种高效提取敏感实体的方法。实验结果显示,语言模型在实体级别上具有较强的记忆能力,需要采用记忆减轻技术以防止隐私侵犯。
本文提出了一种细粒度、基于实体级别的定义来量化语言模型的记忆能力,并提供了一种从自回归语言模型中高效提取敏感实体的方法。实验结果显示,语言模型在实体级别上具有较强的记忆能力,并能够在部分泄露情况下重新生成训练数据。这些发现要求语言模型的训练者在模型记忆方面更加谨慎,采用记忆减轻技术以防止隐私侵犯。
企业监控系统对个人隐私造成严重侵犯,影响心理健康和社会稳定。呼吁加强监管以保护公民权利。
完成下面两步后,将自动完成登录并继续当前操作。