
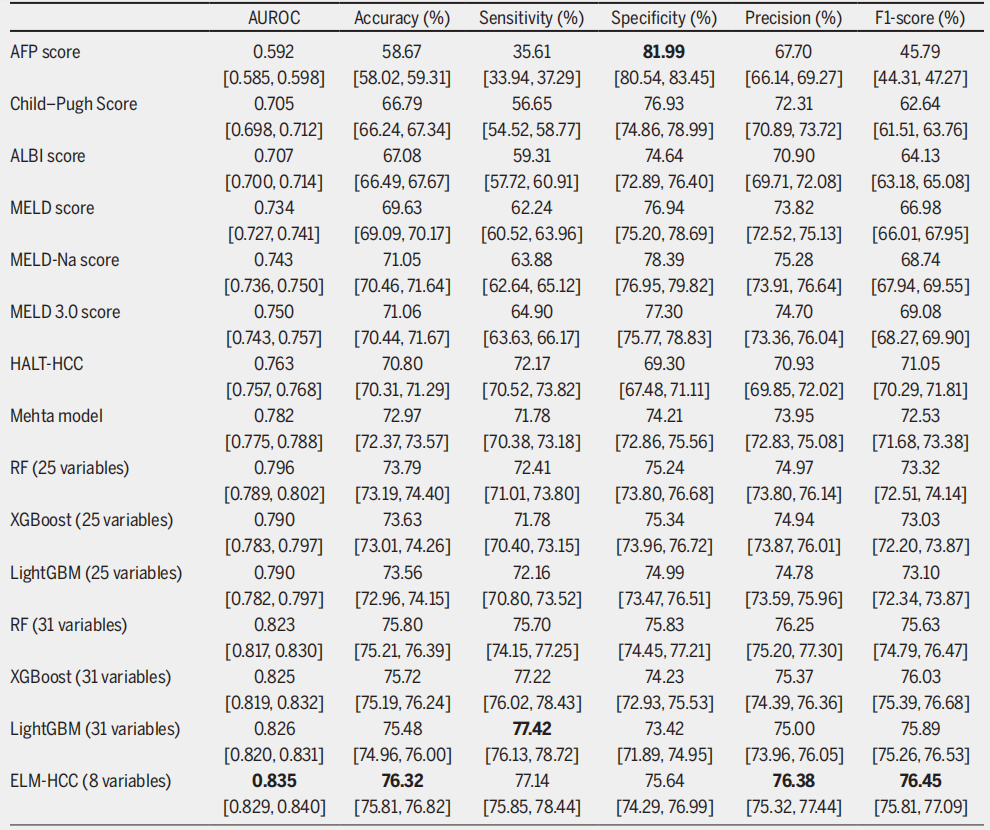
基于11647例临床数据,法国团队首次实现基于机器学习的HCC肝移植双重死亡风险精准预测
HyperAI超神经
·

袋装与提升与堆叠:哪种集成方法在2025年获胜?
MachineLearningMastery.com
·

释放Boosting的力量:集成学习实用指南 - 第三部分
DEV Community
·



探索机器学习在信用卡欺诈检测中的应用
DEV Community
·

随机森林分类:揭示这一强大的机器学习技术如何改变决策制定
DEV Community
·

在 PyTorch 中的过拟合与欠拟合
DEV Community
·
