

如何设计一个帧级别对齐的多源视频播放器
Rust.cc
·




音视频 iOS 面试题 | 音视频面试题集锦 49 期
实时互动网
·

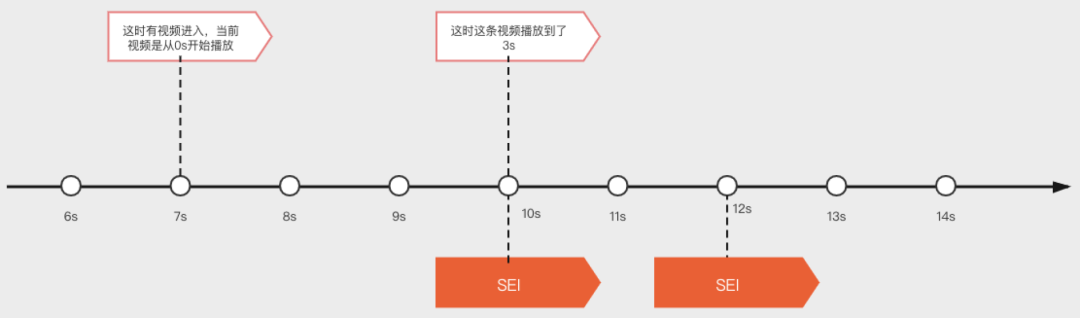
如何利用 SEI 解决音画不同步的问题
实时互动网
·


FFmpeg 播放器入门教程(4):线程分治
实时互动网
·
/cdn.vox-cdn.com/uploads/chorus_asset/file/25819495/hdmibandwidth.jpg)
