




以人为本的设备与始终在线的边缘 AI 音频的兴起
实时互动网
·

预测:游戏音频市场有望增长
实时互动网
·
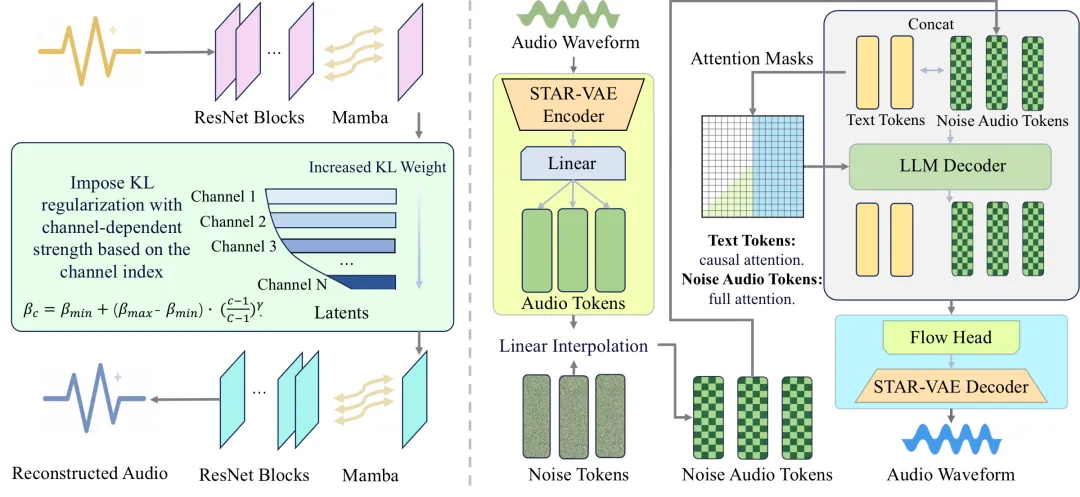


Hydaway 推出实时企业级音频深度伪造检测技术
实时互动网
·
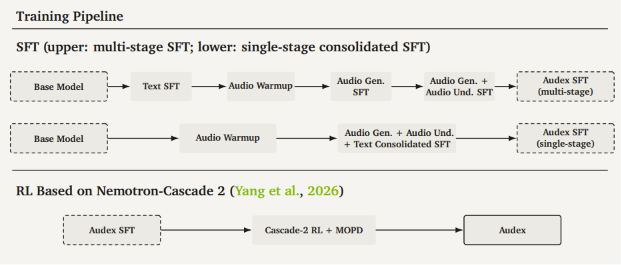

基于长音频编码的分段注意力解码
Apple Machine Learning Research
·
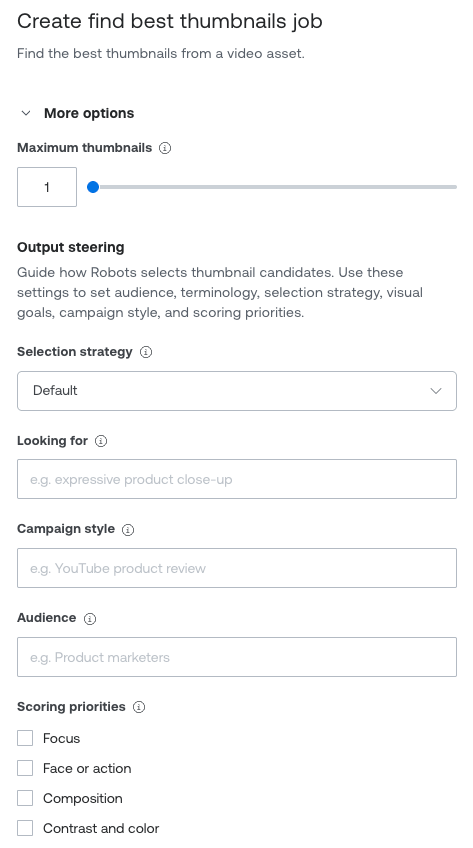
新的Mux Robots工作流程:更好的字幕、音频配音和洞察
Mux Blog - Video technology and more
·

在AI Gateway上构建实时语音代理
Vercel News
·
AI Gateway 现已支持实时语音、语音生成和音频转录
Vercel News
·

xAI Grok音频模型现已在Vercel AI Gateway上线
Vercel News
·

Teenage Engineering为其KO II采样器新增低保真模式、USB音频等功能
The Verge
·

连麦场景下的音频处理最佳实践
实时互动网
·
