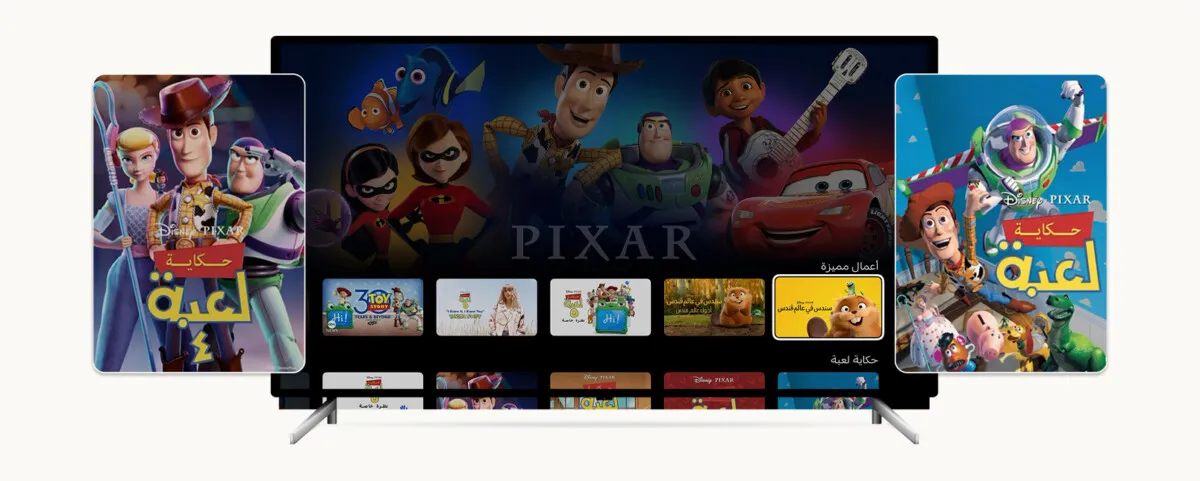
Disney+ 为了更好地服务国际市场,新增了对 17 种音频语言的支持,总语言数达到 58 种。用户界面支持 30 多种语言,字幕提供 42 种语言,更新包括阿拉伯语和希伯来语的右到左界面,强调了本地化在全球流媒体平台的重要性。
Video-LLaMA架构包含视觉-语言和音频-语言两个分支。视觉-语言分支使用Webvid-2M数据集进行预训练,模型生成内容能力强,但指令遵循能力较弱,因此需要微调。第一阶段冻结视觉编码器,使用可训练的视频Q-Former处理帧输入。
完成下面两步后,将自动完成登录并继续当前操作。