
τ0-WM:最大规模预训练的开源具身世界模型来了
量子位
·

AI论文评审:通过生成预训练(GPT-1)提升语言理解
freeCodeCamp.org
·
![如何构建专属语言的大语言模型 [完整手册]](https://cdn.hashnode.com/uploads/covers/5e1e335a7a1d3fcc59028c64/bbdca07e-40a3-4b6e-955f-9573f895154a.png)
如何构建专属语言的大语言模型 [完整手册]
freeCodeCamp.org
·

大语言模型微调实用指南
Databricks
·

人工智能基础
OpenAI
·

LaCy:小型语言模型可以和应该学习的内容不仅仅是损失问题
Apple Machine Learning Research
·

你不知道的大模型训练:原理、路径与新实践
Tw93 的博客
·
从混合到专业领域的语言模型优化分割
Apple Machine Learning Research
·

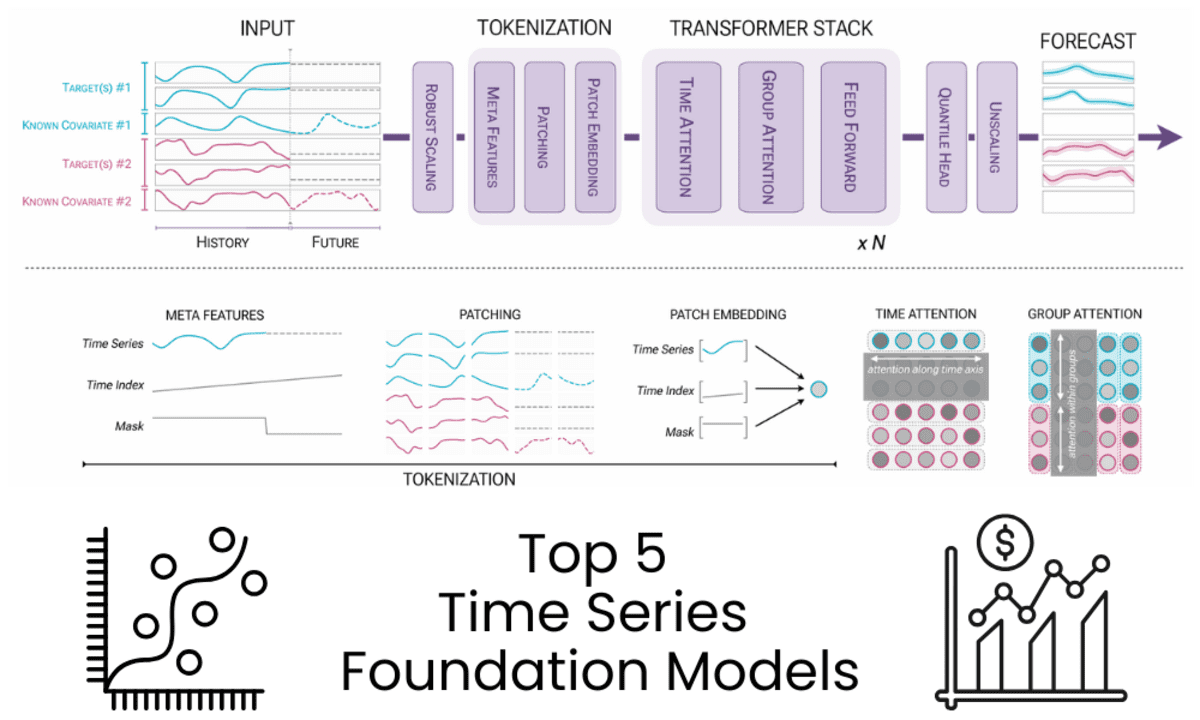
你可能错过的五种时间序列基础模型
KDnuggets
·
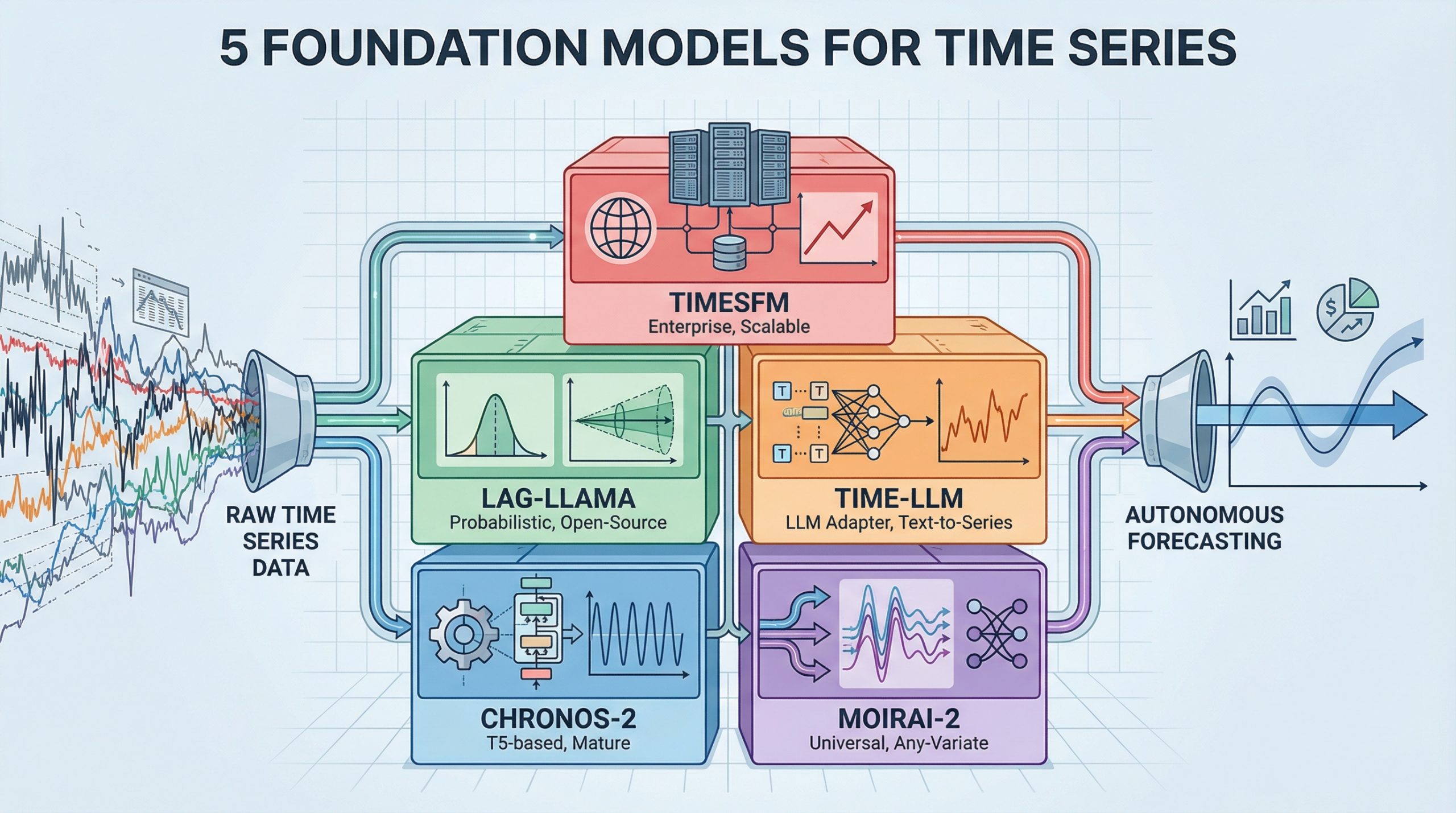
2026年时间序列工具包:5个基础模型实现自主预测
MachineLearningMastery.com
·


基于层次记忆的预训练:区分长尾知识与常识
Apple Machine Learning Research
·
